핵심 요약
- MMU는 CPU와 메모리 사이에서 가상 주소를 물리 주소로 빠르게 변환하여 연속적인 메모리 환상을 만들어내는 핵심 장치입니다.
- 페이징 메커니즘은 메모리를 고정 크기의 프레임으로 나누어 외부 단편화를 해결하고 효율적인 메모리 관리를 가능하게 합니다.
- TLB와 요구 페이징 기술은 주소 변환 속도를 높이고 필요한 데이터만 메모리에 적재하여 시스템 성능을 극대화합니다.
- 현대 운영체제는 페이징을 기반으로 하되 세그멘테이션의 보호 기능을 통합하여 안정성과 효율성을 동시에 확보합니다.
목차
- 서론: 메모리 환상의 마법사, MMU
- 2. 메모리 가상화의 기초 – 주소의 이중성
- 3. 페이징 메커니즘의 핵심 원리 (Deep Dive)
- 4. 성능을 지배하는 기술 – TLB와 요구 페이징
- 5. 세그멘테이션 – 의미 단위의 관리
- 6. 현대 OS의 선택 – 페이징과 세그멘테이션의 공존
- 7. 결론 – 개발자가 이 원리를 알아야 하는 이유
- 자주 묻는 질문 (FAQ)
서론: 메모리 환상의 마법사, MMU
우리가 사용하는 최신 애플리케이션들은 수십 기가바이트(GB)에 달하는 방대한 데이터를 다룹니다. 하지만 놀랍게도 16GB 혹은 32GB의 제한된 물리 메모리(RAM)를 가진 컴퓨터에서도 이 거대한 프로그램들이 충돌 없이, 그것도 동시에 여러 개가 매끄럽게 실행됩니다. 이 불가능해 보이는 일을 가능하게 만드는 기술의 핵심에는 페이징 메커니즘이 자리 잡고 있습니다.
사용자나 프로그래머가 보는 메모리의 모습과 실제 컴퓨터 하드웨어 내부의 메모리 모습은 완전히 다릅니다. 프로그래머에게 메모리는 0번지부터 시작해서 끝없이 이어지는 ‘연속된’ 공간처럼 보입니다. 하지만 실제 물리 메모리는 여기저기 흩어져 있는 조각난 공간일 뿐입니다. 그렇다면 연속되지 않은 물리 메모리 조각들을 어떻게 CPU는 연속된 공간처럼 인식할까요?
이 마법을 부리는 주인공이 바로 MMU(Memory Management Unit, 메모리 관리 장치)입니다. 오늘 우리는 현대 운영체제(OS)가 하드웨어와 협력하여 어떻게 이 거대한 ‘메모리 환상’을 만들어내는지, 그 이면에 숨겨진 치밀한 기술적 원리를 파헤쳐 보겠습니다. 단순히 개념을 아는 것을 넘어, 시스템 성능 최적화의 단서가 되는 페이징 메커니즘의 심연을 들여다볼 시간입니다.
부가 설명: MMU가 중요한 이유
우리가 코드를 작성할 때 malloc이나 new를 통해 메모리를 할당받으면, 운영체제는 가상 주소를 건네줍니다. 만약 MMU가 없다면 프로그래머는 실제 RAM의 어떤 주소가 비어있는지 일일이 확인하고 관리해야 할 것입니다. MMU는 CPU와 메인 메모리 사이에 위치한 하드웨어 칩으로, 눈깜짝할 사이에 가상 주소를 물리 주소로 변환해줍니다. 덕분에 개발자는 물리 메모리의 복잡한 상황을 전혀 신경 쓰지 않고 오로지 로직 구현에만 집중할 수 있는 것입니다. 이 과정은 투명하게 이루어지기 때문에 우리는 그 존재를 잊기 쉽지만, 시스템 성능에 지대한 영향을 미칩니다.

2. 메모리 가상화의 기초 – 주소의 이중성
운영체제의 메모리 관리를 이해하기 위해서는 먼저 ‘주소(Address)’가 두 가지 얼굴을 가지고 있다는 사실을 명확히 해야 합니다. 우리가 프로그램 코드에서 변수를 선언하고 포인터로 가리키는 주소는 실제 RAM의 위치가 아닙니다. 이를 구분하기 위해 우리는 두 가지 개념을 사용합니다.
- 논리 주소 (Logical Address): 가상 주소(Virtual Address)라고도 불립니다. CPU가 생성하는 주소이며, 실행 중인 프로그램이 독점적으로 메모리를 사용하는 것처럼 느끼게 해주는 가상화된 주소입니다.
- 물리 주소 (Physical Address): 실제 메모리 하드웨어(RAM) 상의 고유한 위치값입니다. 데이터가 실제로 저장되는 전기적 위치를 의미합니다.
이 두 주소 사이의 괴리를 메우는 것이 바로 가상 주소와 물리 주소 매핑입니다. 다중 프로그래밍 환경에서는 여러 프로세스가 동시에 메모리에 올라와야 합니다. 이때 각 프로세스가 서로의 메모리 영역을 침범하지 못하도록 보호(Protection)하고, 물리 메모리의 남는 공간 어디에든 효율적으로 배치(Relocation)하기 위해서는 이 매핑 과정이 필수적입니다.
이 변환 과정은 소프트웨어적으로 처리하기에는 너무 빈번하게 발생합니다. CPU가 명령어를 수행할 때마다 메모리 참조가 일어나기 때문입니다. 따라서 앞서 언급한 MMU라는 전용 하드웨어가 고속으로 가상 주소와 물리 주소 매핑을 수행합니다. 기준 레지스터(Base Register) 등을 활용해 CPU가 요청한 논리 주소에 특정 값을 더해 물리 주소로 변환하는 것이 가장 기초적인 원리입니다.
부가 설명: 주소 바인딩(Address Binding)의 시점
가상 주소와 물리 주소 매핑이 언제 이루어지느냐에 따라 시스템의 유연성이 달라집니다.
- 컴파일 타임: 컴파일 시점에 물리 주소가 정해지면, 프로그램 위치를 바꿀 수 없습니다. (과거 방식)
- 로드 타임: 프로그램이 메모리에 적재될 때 주소가 결정됩니다. 실행 중 이동이 불가능합니다.
- 실행 타임(Execution Time): 현대 OS가 채택한 방식입니다. 프로그램 실행 도중에도 물리 주소가 바뀔 수 있습니다. 이를 지원하기 위해 MMU 하드웨어의 지원이 필수적입니다. 이 방식 덕분에 우리는 메모리 부족 시 데이터를 디스크로 잠시 쫓아내는 ‘스와핑(Swapping)’ 기술을 사용할 수 있습니다.
3. 페이징 메커니즘의 핵심 원리 (Deep Dive)
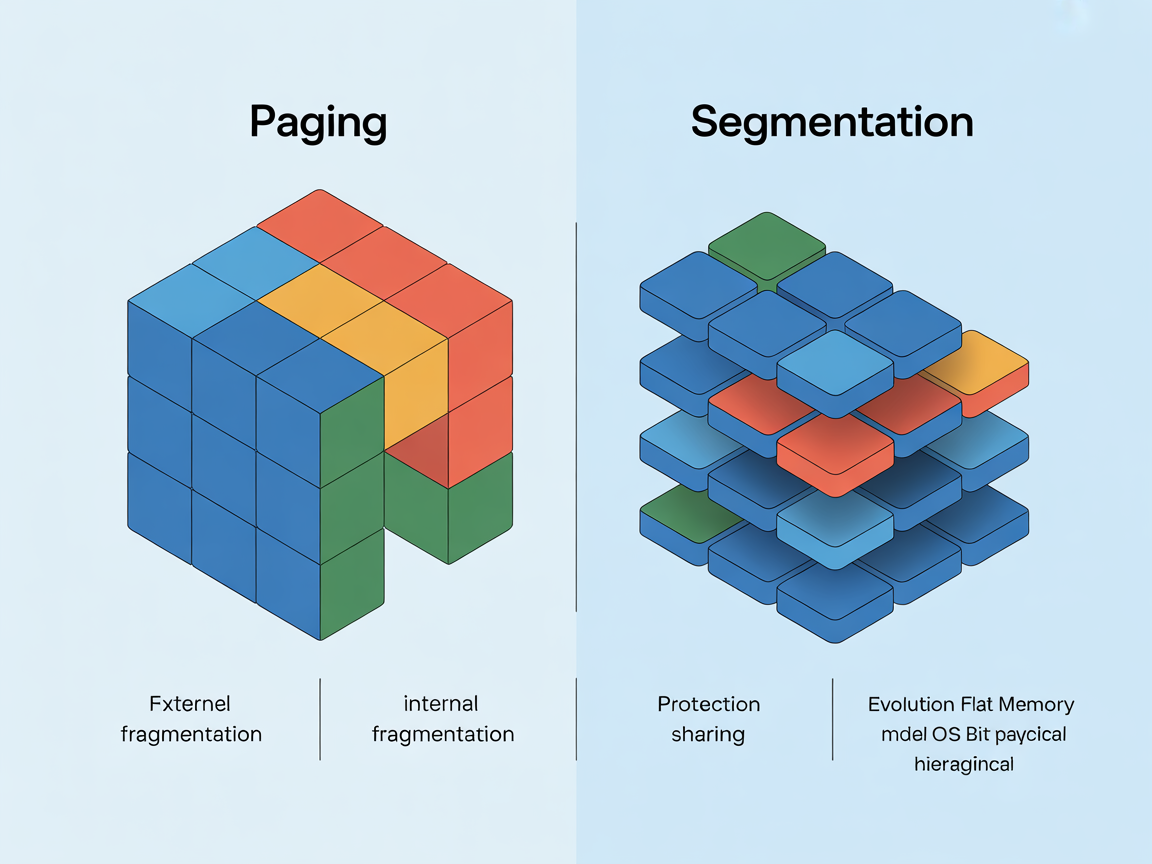
연속 메모리 할당 방식은 치명적인 단점이 있었습니다. 프로세스들이 메모리에 들어왔다 나갔다를 반복하다 보면, 남은 공간들이 너무 작게 쪼개져서 정작 큰 프로세스가 들어갈 수 없는 현상이 발생합니다. 이를 외부 단편화(External Fragmentation)라고 합니다. 이 문제를 해결하기 위해 등장한 구세주가 바로 페이징 메커니즘입니다.
페이징의 정의와 구조
페이징은 물리 메모리를 고정된 크기의 블록인 프레임(Frame)으로 나누고, 가상 메모리(논리 메모리)를 이와 동일한 크기의 페이지(Page)로 나누어 관리하는 기법입니다.
이렇게 하면 더 이상 프로세스를 연속된 공간에 억지로 구겨 넣을 필요가 없습니다. 프로세스를 페이지 단위로 잘게 쪼갠 뒤, 물리 메모리의 빈 프레임 아무 곳에나 흩뿌려 놓을 수 있기 때문입니다. 즉, 물리 메모리가 뒤죽박죽 섞여 있어도 CPU는 페이지 테이블(Page Table)이라는 지도를 통해 순서대로 데이터를 읽어올 수 있습니다.
주소 변환 공식
페이징 시스템에서 가상 주소(v)는 두 부분으로 나뉩니다.
- 페이지 번호 (p): 페이지 테이블의 인덱스입니다.
- 오프셋 (d): 페이지 내부에서의 위치 변위입니다.
주소 변환 과정은 다음과 같습니다:
- CPU가 가상 주소 v = (p, d)를 요청합니다.
- MMU는 페이지 테이블에서 페이지 번호 p를 찾아 해당하는 프레임 번호 (f)를 얻습니다.
- 이 프레임 번호 f에 기존의 오프셋 d를 그대로 붙입니다.
- 최종 물리 주소는 p = (f, d)가 됩니다.
가상 주소와 물리 주소 매핑의 비교
| 구분 | 논리 주소 (Virtual Address) | 물리 주소 (Physical Address) |
|---|---|---|
| 구성 요소 | 페이지 번호 (p) + 오프셋 (d) | 프레임 번호 (f) + 오프셋 (d) |
| 생성 주체 | CPU (프로세스 관점) | 메모리 하드웨어 관점 |
| 변환 도구 | 페이지 테이블 (Page Table) | (변환 결과물) |
페이징의 한계: 내부 단편화
페이징 메커니즘은 외부 단편화를 완벽하게 해결합니다. 하지만 빛이 있으면 그림자가 있듯, 내부 단편화(Internal Fragmentation)라는 새로운 문제가 생깁니다. 예를 들어 페이지 크기가 4KB인데, 프로세스의 마지막 조각이 1KB만 필요하다면, 나머지 3KB는 버려지는 공간이 됩니다. 하지만 이는 외부 단편화로 인해 전체 메모리를 활용 못 하는 것에 비하면 아주 미미한 낭비이므로 현대 시스템은 이를 감수합니다.
부가 설명: 페이지 테이블의 크기 문제
모든 프로세스는 자신만의 페이지 테이블을 가집니다. 문제는 현대 시스템처럼 64비트 주소 체계를 사용하면, 페이지 테이블 자체의 크기가 어마어마하게 커진다는 점입니다. 이를 해결하기 위해 현대 OS는 ‘계층적 페이징(Hierarchical Paging)’ 또는 ‘해시 페이지 테이블’ 같은 기법을 사용하여 페이지 테이블이 차지하는 메모리 공간을 최적화합니다. 즉, 페이지 테이블을 위한 페이지 테이블을 만드는 방식으로 메모리 낭비를 줄이는 것입니다.
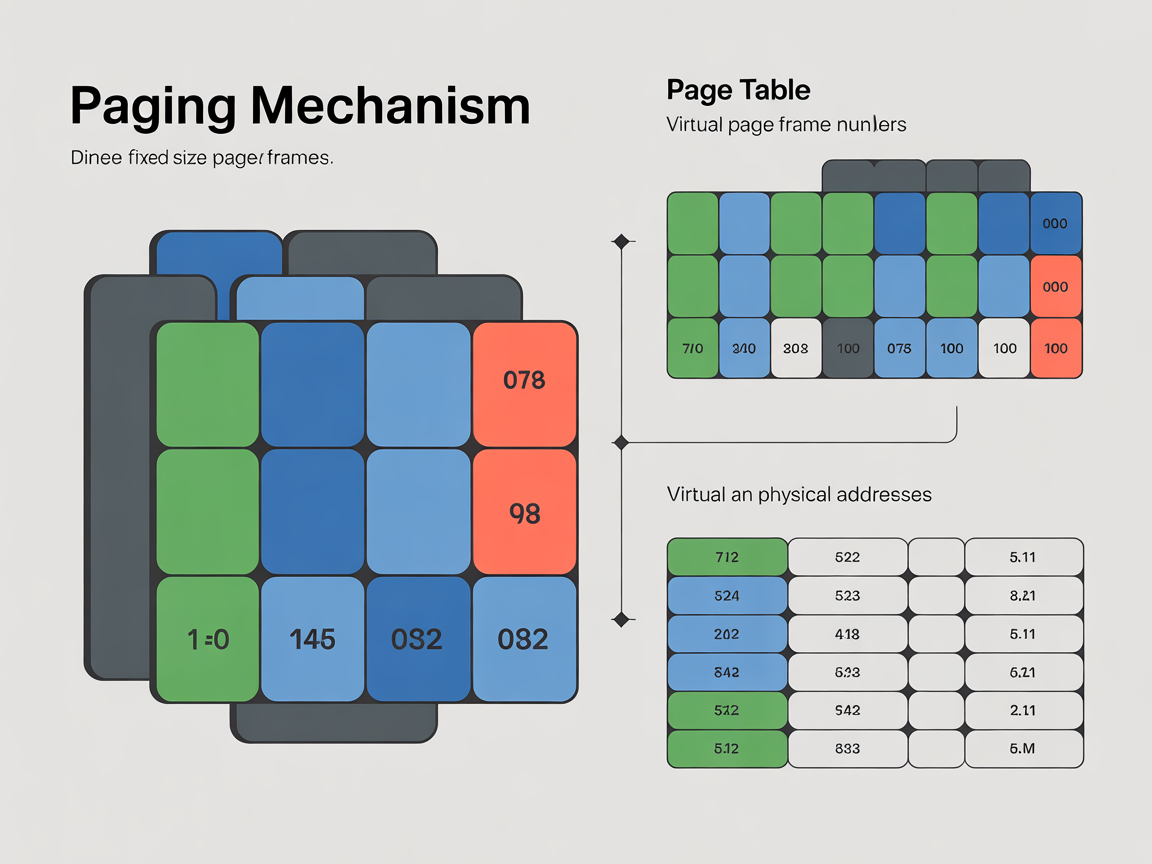
4. 성능을 지배하는 기술 – TLB와 요구 페이징
기본적인 페이징 이론은 완벽해 보이지만, 실제 구현에서는 속도 문제가 발생합니다. 메모리에 있는 페이지 테이블을 한 번 읽고, 실제 데이터를 읽으러 또 메모리에 가야 하므로, 최소 2번의 메모리 접근이 필요하기 때문입니다. 이를 해결하고 성능을 극대화하기 위해 현대 OS는 TLB와 요구 페이징 기술을 사용합니다.
TLB (Translation Lookaside Buffer): 하드웨어 캐시의 힘
TLB는 MMU 내부에 있는 작지만 매우 빠른 하드웨어 캐시 메모리입니다. 최근에 변환된 ‘페이지 번호’와 ‘프레임 번호’의 쌍을 저장하고 있습니다.
- TLB Hit: CPU가 요청한 페이지 번호가 TLB에 있다면, 메모리에 있는 페이지 테이블을 거치지 않고 즉시 물리 주소를 얻습니다. (매우 빠름)
- TLB Miss: TLB에 없다면, 어쩔 수 없이 메모리의 페이지 테이블을 조회합니다. 그리고 이 정보를 TLB에 업데이트하여 다음번엔 빠르게 찾을 수 있게 합니다.
TLB의 적중률(Hit Ratio)이 시스템 전체 성능을 좌우한다고 해도 과언이 아닙니다.
요구 페이징 (Demand Paging): 게으름의 미학
현대 OS는 프로그램을 실행할 때, 모든 데이터를 물리 메모리에 미리 올리지 않습니다. 당장 실행에 필요한 페이지만 올리고, 나머지는 디스크에 놔둡니다. 이를 ‘Lazy Loading’ 또는 요구 페이징이라고 합니다.
- 메모리 절약: 필요한 것만 올리므로 더 많은 프로세스를 동시에 실행할 수 있습니다.
- 빠른 응답: 프로그램 전체 로딩을 기다릴 필요 없이 즉시 시작할 수 있습니다.
페이지 폴트 (Page Fault): 위기를 기회로
CPU가 요청한 페이지가 현재 물리 메모리에 없을 때 발생하는 인터럽트를 페이지 폴트라고 합니다. 이는 오류라기보다 OS가 디스크에서 데이터를 가져오기 위한 신호입니다.
페이지 폴트 처리 과정 (Step-by-Step):
- Trap 발생: CPU가 유효하지 않은 페이지에 접근하면 하드웨어 트랩이 발생하여 OS로 제어권이 넘어갑니다.
- 디스크 탐색: OS는 해당 페이지가 디스크의 어디에 있는지 확인합니다.
- 빈 프레임 확보: 물리 메모리에 빈 공간을 찾습니다. (꽉 찼다면 페이지 교체 알고리즘(LRU 등)을 통해 누군가를 쫓아냅니다.)
- 데이터 로드: 디스크에서 데이터를 읽어 메모리 프레임에 적재합니다. (이 과정은 매우 느리므로, 그동안 CPU는 다른 프로세스를 실행합니다.)
- 테이블 갱신: 페이지 테이블에 ‘유효(Valid)’ 표시를 하고 프레임 번호를 기록합니다.
- 명령어 재실행: 중단되었던 명령어를 처음부터 다시 실행합니다.
부가 설명: 스래싱(Thrashing)의 공포
요구 페이징은 효율적이지만, 물리 메모리가 턱없이 부족하여 페이지 폴트가 너무 빈번하게 발생하면 문제가 됩니다. CPU가 실제 작업을 하는 시간보다 페이지를 교체하느라 디스크 I/O를 하는 시간이 더 길어지는 현상을 스래싱(Thrashing)이라고 합니다. 컴퓨터가 멈춘 것처럼 버벅거리는 현상의 주범입니다. 이를 막기 위해 OS는 ‘워킹 셋(Working Set)’ 알고리즘 등을 통해 프로세스가 원활히 돌기 위한 최소한의 프레임을 보장하려 노력합니다.
5. 세그멘테이션 – 의미 단위의 관리
페이징이 물리적인 크기(Frame)에 맞춘 기계적인 분할이라면, 세그멘테이션은 프로그래머가 인지하는 논리적인 단위로 메모리를 자르는 기법입니다.
세그멘테이션의 정의
프로세스를 코드(Code), 데이터(Data), 스택(Stack), 힙(Heap)과 같이 의미 있는 단위인 ‘세그먼트(Segment)’로 나눕니다. 각 세그먼트는 크기가 제각각입니다.
세그멘테이션 주소 변환과 보호
세그멘테이션 주소 변환은 세그먼트 번호(s)와 오프셋(d)을 사용합니다. 페이징과 달리 세그먼트는 크기가 다양하므로, 하드웨어적인 보호 기능이 더 중요합니다.
- 기준 레지스터 (Base): 해당 세그먼트가 물리 메모리의 어디서 시작하는지(시작 주소)를 나타냅니다.
- 한계 레지스터 (Limit): 해당 세그먼트의 크기(길이)를 나타냅니다.
만약 오프셋 d가 한계 레지스터 값보다 크다면? 이는 프로세스가 자신에게 할당된 영역을 벗어나 불법적인 접근을 시도한 것입니다. 이때 그 유명한 ‘Trap’이 발생하며 OS는 프로그램을 강제 종료시킵니다. 이 방식은 코드 영역은 ‘읽기 전용’, 데이터 영역은 ‘읽기/쓰기’ 등으로 권한을 부여하기가 페이징보다 훨씬 직관적이고 공유(Sharing)가 용이합니다.
세그멘테이션의 치명적 단점
세그먼트들의 크기가 서로 다르기 때문에, 메모리 해제와 할당을 반복하다 보면 중간중간 남는 공간이 생기지만 어떤 세그먼트도 들어갈 수 없는 외부 단편화 문제가 다시 발생합니다. 이는 페이징이 해결했던 문제를 다시 불러오는 꼴이 됩니다.
부가 설명: 공유 메모리의 이점
세그멘테이션의 가장 큰 장점 중 하나는 ‘공유’입니다. 예를 들어, 워드 프로세서 프로그램이 10개 실행된다고 가정해 봅시다. 프로그램의 핵심 코드(Code Segment)는 10개 모두 동일합니다. 세그멘테이션을 사용하면 이 코드 영역만 따로 떼어내어 물리 메모리 한 곳에만 올리고, 10개의 프로세스가 이를 공유하게 할 수 있습니다. 이를 통해 엄청난 메모리 절약 효과를 얻을 수 있습니다. 물론 페이징에서도 가능하지만, 세그멘테이션이 논리적 단위로 나뉘어 있어 설정이 훨씬 자연스럽습니다.
6. 현대 OS의 선택 – 페이징과 세그멘테이션의 공존
지금까지 살펴본 두 기술은 각기 장단점이 뚜렷합니다.
페이징 vs 세그멘테이션 비교 요약
| 특징 | 페이징 (Paging) | 세그멘테이션 (Segmentation) |
|---|---|---|
| 분할 단위 | 고정 크기 (Page) | 가변 크기 (Logical Unit) |
| 장점 | 외부 단편화 해결, 메모리 관리 단순화 | 보호(Protection)와 공유(Sharing) 용이 |
| 단점 | 내부 단편화 발생, 복잡한 공유 | 외부 단편화 발생, 메모리 배치 복잡 |
그렇다면 Windows나 Linux 같은 현대 OS는 무엇을 선택했을까요? 정답은 “둘 다 사용하거나, 페이징을 기반으로 한다”입니다.
과거에는 Paged Segmentation이라는 기법을 사용했습니다. 먼저 프로세스를 의미 단위인 세그먼트로 나누고, 각 세그먼트를 다시 고정 크기의 페이지로 나누어 물리 메모리에 할당하는 방식입니다. 이렇게 하면 세그멘테이션의 장점인 보호/공유 기능과 페이징의 장점인 외부 단편화 해결을 모두 잡을 수 있습니다.
하지만 최신 x86-64 아키텍처와 OS(Linux 등)에서는 Flat Memory Model을 주로 사용하며 순수한 페이징 기법이 지배적입니다. 64비트 환경에서는 주소 공간이 워낙 광활하여 세그멘테이션을 통한 복잡한 주소 변환보다는, 페이징 하나만으로 관리하는 것이 효율적이기 때문입니다. 단, 가상 주소와 물리 주소 매핑의 효율을 위해 페이징 테이블 내에 권한 비트(R/W/X)를 두어 세그멘테이션이 하던 보호 기능을 페이징 메커니즘 내부로 흡수하여 구현하고 있습니다.
부가 설명: 64비트 시대의 변화
인텔의 x86-64 아키텍처에서는 세그멘테이션 기능이 호환성 유지를 위해 남아있기는 하지만, 사실상 거의 사용되지 않습니다(Base를 0으로 고정). 대신 4단계 혹은 5단계의 멀티 레벨 페이징을 사용하여 광활한 주소 공간을 관리합니다. 즉, 현대의 가상 주소와 물리 주소 매핑은 하드웨어 성능의 발전과 함께 ‘순수 페이징’에 ‘세그멘테이션의 철학(보호 기능)’을 소프트웨어적으로 녹여내는 방향으로 진화했습니다.
7. 결론 – 개발자가 이 원리를 알아야 하는 이유
우리는 지금까지 MMU, TLB, 페이지 폴트, 그리고 페이징 메커니즘과 세그멘테이션까지, 운영체제 메모리 관리의 심장을 해부해 보았습니다.
개발자가 이 깊은 내용을 알아야 하는 이유는 명확합니다. 여러분이 C/C++로 개발하다 마주치는 Segmentation Fault 에러는 단순히 세그멘테이션 기법의 오류가 아니라, 프로세스가 허가받지 않은 메모리 영역(엄밀히 말하면 페이지)에 접근하려다 OS에게 차단당했다는 뜻입니다. 또한, 대용량 데이터를 처리하는 서버 애플리케이션의 성능이 이유 없이 떨어진다면, 과도한 페이지 폴트가 발생하고 있는 것은 아닌지 의심해 볼 수 있는 통찰력을 가질 수 있습니다.
화려한 UI와 빠른 서비스 뒤에는, 조각난 메모리를 이어 붙이고 0.0001초라도 더 빨리 데이터를 배달하기 위해 분투하는 운영체제의 보이지 않는 노력이 숨어 있습니다. 이 원리를 이해하는 것은 단순한 코더를 넘어, 시스템 전체를 조망하는 아키텍트(Architect)로 성장하는 첫걸음이 될 것입니다.
부가 설명: 실무 적용 팁
리눅스 환경에서 개발한다면 vmstat이나 top 명령어를 통해 시스템의 si(swap in), so(swap out) 수치를 확인해 보세요. 이 수치가 높다면 현재 시스템은 메모리가 부족하여 페이지 교체 작업(페이지 폴트 처리)에 과도한 자원을 쓰고 있다는 신호입니다. 이때는 메모리를 증설하거나, 애플리케이션의 메모리 참조 지역성(Locality)을 개선하는 튜닝이 필요합니다. 이론을 알면 모니터링 수치가 살아서 말을 걸어올 것입니다.
자주 묻는 질문 (FAQ)
Q: 페이징과 세그멘테이션의 가장 큰 차이점은 무엇인가요?
A: 페이징은 메모리를 고정된 크기(Page/Frame)로 나누는 물리적 분할 방식이며, 세그멘테이션은 코드, 데이터 등 논리적 의미 단위로 나누는 방식입니다. 페이징은 외부 단편화 해결에 유리하고, 세그멘테이션은 보호와 공유에 유리합니다.
Q: 페이지 폴트(Page Fault)는 시스템 오류인가요?
A: 아니요, 오류가 아닙니다. CPU가 요청한 데이터가 현재 물리 메모리에 없어 디스크에서 가져와야 함을 알리는 정상적인 운영체제 매커니즘입니다. 다만, 너무 빈번하게 발생하면 시스템 성능 저하(스래싱)를 유발할 수 있습니다.
Q: MMU가 없으면 가상 메모리를 사용할 수 없나요?
A: 네, 거의 불가능합니다. 가상 주소를 물리 주소로 변환하는 작업은 CPU 명령어가 실행될 때마다 일어나야 하므로 매우 빨라야 합니다. 소프트웨어만으로는 이 속도를 감당할 수 없기 때문에 MMU라는 하드웨어의 지원이 필수적입니다.