핵심 요약
- 명령어 인출 과정은 CPU가 작업을 수행하기 위해 메모리에서 명령어를 가져오는 가장 첫 번째이자 핵심적인 단계입니다.
- CPU 작동 원리는 요리사(CPU)가 냉장고(메모리)에서 재료를 꺼내 도마(레지스터)에서 요리하는 과정에 비유할 수 있습니다.
- PC, MAR, MBR, IR 등의 레지스터는 데이터와 주소를 임시 저장하며 사이클을 매끄럽게 연결하는 역할을 합니다.
- 인출, 해석, 실행의 반복적인 사이클을 통해 컴퓨터의 모든 복잡한 작업이 처리됩니다.
목차
- CPU 명령어 사이클을 이해하기 위한 필수 용어
- 사이클의 시작, 명령어 인출(Fetch) 과정
- 암호를 해독하는 명령어 해석(Decode) 과정
- 실제 작업을 수행하는 명령어 실행(Execute) 과정
- 전체 흐름 요약 및 시각적 정리
- 결론
- 자주 묻는 질문
컴퓨터의 두뇌인 CPU가 모든 작업을 시작하기 위해 가장 먼저 수행하는 단계, 바로 명령어 인출 과정입니다. 2026년 현재 우리는 AI 프로세서와 양자 컴퓨터가 뉴스를 장식하는 최첨단 시대에 살고 있습니다. 하지만 놀랍게도 우리가 매일 사용하는 스마트폰, 노트북, 그리고 고성능 게이밍 PC의 핵심 작동 원리는 수십 년 전 정립된 ‘폰 노이만 구조’를 그대로 따르고 있습니다.
여러분이 키보드의 키를 하나 누르거나 게임을 실행하는 찰나의 순간에도, CPU 내부에서는 초당 수십억 번의 사이클이 반복됩니다. 복잡해 보이는 이 과정도 사실은 ‘가져오고(Fetch), 해석하고(Decode), 실행하는(Execute)’ 세 가지 단계의 무한 반복일 뿐입니다. 오늘 이 글에서는 전공자들만 아는 어려운 용어를 요리사에 비유해 아주 쉽게 풀어드리고, 핵심인 명령어 인출 과정을 중심으로 CPU의 비밀을 완벽하게 파헤쳐 드리겠습니다.

1. CPU 명령어 사이클을 이해하기 위한 필수 용어 (Prerequisites)
본격적인 사이클을 알아보기 전에, CPU라는 ‘요리사’가 사용하는 도구들의 이름을 먼저 알아야 합니다. CPU 내부에는 데이터를 아주 빠르게 저장하는 작은 기억 장소들이 있는데, 이를 레지스터(Register)라고 부릅니다.
마치 요리사가 재료를 냉장고(메모리)에서 꺼내 도마(레지스터) 위에 올려두고 요리하는 것과 같습니다. 냉장고까지 왔다 갔다 하는 것보다 도마 위에 있는 재료를 쓰는 게 훨씬 빠르기 때문입니다.
사이클 이해를 위해 꼭 알아야 할 핵심 레지스터를 아래 표로 정리했습니다.
| 레지스터 이름 | 약어 | 역할 비유 (요리사) | 실제 역할 설명 |
|---|---|---|---|
| 프로그램 카운터 | PC | 주문서 번호표 | 다음에 실행할 명령어가 저장된 메모리 주소를 가리킵니다. |
| 메모리 주소 레지스터 | MAR | 주소 메모장 | 데이터를 찾으러 가기 전, 그 주소를 잠시 적어두는 공간입니다. |
| 메모리 버퍼 레지스터 | MBR (또는 MDR) | 재료 바구니 | 메모리에서 가져온 데이터나 명령어를 잠시 담아두는 곳입니다. |
| 명령어 레지스터 | IR | 요리 작업대 | 현재 해석하고 실행 중인 명령어가 놓이는 곳입니다. |
| 누산기 | AC | 중간 계산 그릇 | 연산 장치(ALU)가 계산한 결과를 일시적으로 저장합니다. |
💡 추가 정보: 이 외에도 연산을 담당하는 계산기인 ALU, 연산 결과가 양수인지 음수인지 등의 상태를 기록하는 플래그 레지스터(Status Register)도 있습니다. 이 모든 도구들이 유기적으로 움직이며 하나의 명령을 처리합니다. 이제 도구 사용법을 익혔으니, 실제 명령어 인출 과정으로 들어가 보겠습니다.
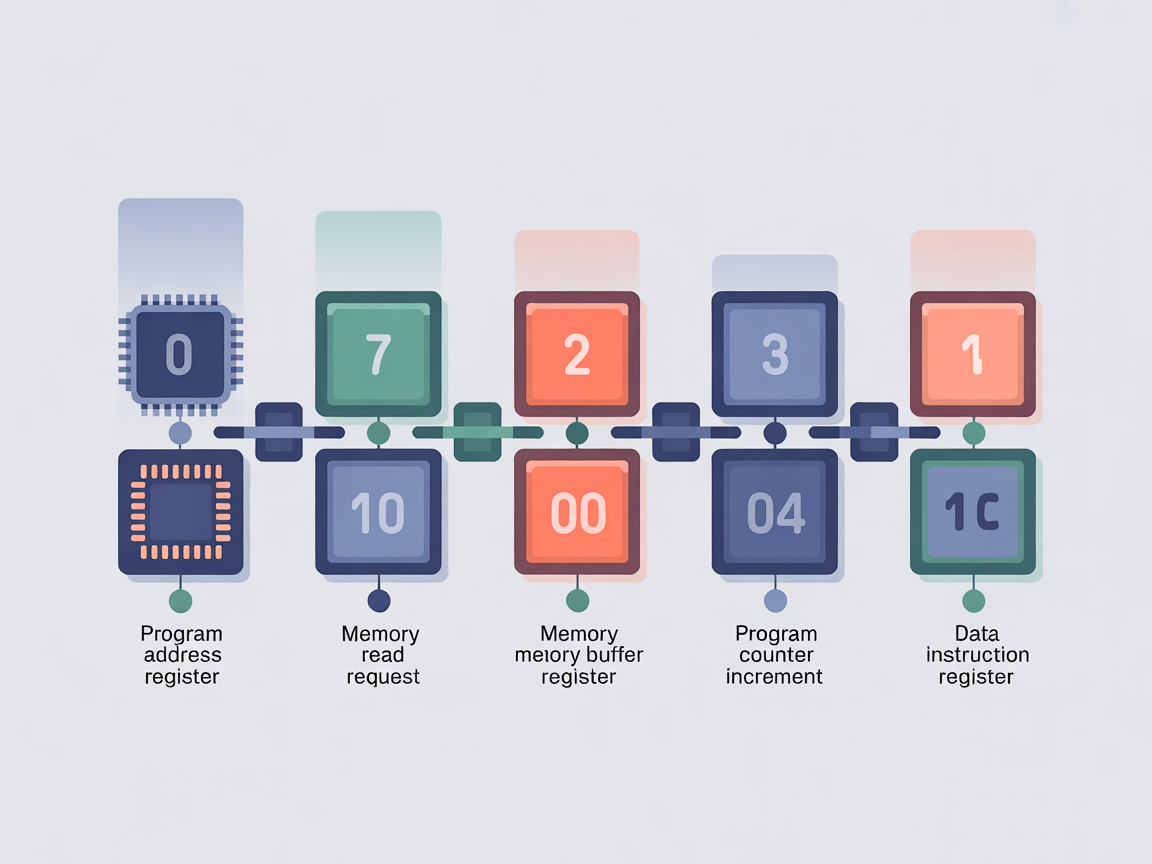
2. 사이클의 시작, 명령어 인출(Fetch) 과정
모든 작업의 시작은 메모리에 저장된 명령어를 CPU 내부로 가져오는 것입니다. 이를 명령어 인출 과정, 혹은 영문으로 Fetch(페치) 단계라고 합니다. 이 단계가 없으면 CPU는 무엇을 해야 할지 전혀 알 수 없습니다.
명령어 인출 과정은 아주 정교한 순서로 이루어집니다. 데이터가 레지스터 사이를 어떻게 이동하는지, 슬로우 모션으로 보듯 단계별로 살펴보겠습니다.
- 주소 전달 [PC → MAR]: 가장 먼저, 나침반 역할을 하는 PC가 “이번에 실행할 명령어는 100번지에 있어”라고 알려줍니다. 이 주소 값(100)을 MAR(메모리 주소 레지스터)로 복사합니다.
- 메모리 읽기 요청 [Memory Read]: 제어 장치가 메모리에 “MAR에 적힌 주소의 내용을 내놔!”라고 읽기 신호를 보냅니다. 동시에 제어 버스를 통해 신호가 전달됩니다.
- 데이터 이동 [Memory → MBR]: 메모리는 100번지에 있던 내용(명령어)을 데이터 버스에 실어 보냅니다. 이 데이터는 CPU의 현관문인 MBR(메모리 버퍼 레지스터)에 도착합니다.
- 다음 순서 준비 [PC 증가]: 명령어 인출 과정이 일어나는 동안, PC는 쉴 새 없이 다음을 준비합니다. 현재 명령어를 가져왔으니, 다음 명령어를 가리키기 위해 자신의 값을 1 증가시킵니다. (PC ← PC + 1)
- 작업대 안착 [MBR → IR]: 마지막으로 MBR에 임시 보관된 명령어가 해석을 위해 IR(명령어 레지스터)로 이동합니다.
💡 심화 포인트: 이 모든 명령어 인출 과정은 CPU의 심장박동인 ‘클록(Clock)’에 맞춰 딱딱 떨어지게 진행됩니다. 예를 들어 첫 박자에 주소를 보내고, 두 번째 박자에 데이터를 읽어오는 식입니다. 이처럼 명령어 인출 과정은 CPU가 쉬지 않고 수행하는 가장 기초적이고 중요한 루틴입니다.
3. 암호를 해독하는 명령어 해석(Decode) 과정
명령어 인출(fetch) 과정을 통해 작업대(IR)에 명령어가 도착했습니다. 하지만 이 명령어는 0과 1로 이루어진 기계어라서, 아직 무슨 뜻인지 모릅니다. 이제 이 암호를 푸는 명령어 해석(decode) 과정이 필요합니다.
제어 장치 내의 ‘해독기(Decoder)’는 IR에 담긴 비트 패턴을 분석합니다. 이때 명령어는 크게 두 부분으로 나뉩니다.
- 연산 코드 (Opcode): ‘무엇을 할 것인가?’ (예: 더해라, 가져와라, 이동해라)
- 오퍼랜드 (Operand): ‘무엇을 가지고?’ (예: 숫자 10과, 200번지의 데이터를)
예를 들어 LOAD 500이라는 명령어가 있다면, 해독기는 “500번지(Operand)에 있는 데이터를 가져와라(Opcode)”라고 해석합니다. 해석이 끝나면 제어 장치는 ALU나 메모리에 보낼 전기적 제어 신호를 생성합니다.
🔍 전문가 팁 (Pro Tip): 간접 사이클 (Indirect Cycle)
만약 오퍼랜드가 실제 데이터가 아니라, ‘데이터가 있는 주소의 주소’를 가리키는 경우가 있습니다. 마치 보물지도를 찾았는데, 거기에 또 다른 지도의 위치가 적혀 있는 것과 같죠. 이를 ‘간접 주소 지정’이라고 합니다. 이때는 명령어 해석(decode) 과정 직후에 실제 주소를 찾기 위해 메모리를 한 번 더 다녀오는 간접 사이클(Indirect Cycle)이 추가됩니다.
4. 실제 작업을 수행하는 명령어 실행(Execute) 과정
해석이 끝났으면 이제 행동으로 옮길 차례입니다. 명령어 실행(execute) 과정에서는 해석된 내용에 따라 실제 연산이나 데이터 이동이 일어납니다. 실행의 형태는 명령어의 종류에 따라 다양합니다.
주요 실행 유형:
- 데이터 전송: 메모리에서 레지스터로 데이터를 가져오거나(LOAD), 반대로 저장합니다(STORE).
- 데이터 처리: ALU(산술논리연산장치)를 이용해 덧셈(ADD), 뺄셈(SUB), 논리 곱(AND) 등의 계산을 수행합니다.
- 제어 흐름 변경: PC의 값을 강제로 바꾸어 프로그램의 실행 순서를 점프(JUMP) 시킵니다.
연산이 끝나면 그 결과는 AC(누산기) 같은 레지스터에 저장되거나, 필요시 메모리에 다시 기록(Write-back)되면서 명령어 실행(execute) 과정은 마무리됩니다.
⚠️ 중요한 체크포인트: 인터럽트(Interrupt)
실행이 끝났다고 바로 다음 명령어 인출 과정으로 넘어가는 것은 아닙니다. CPU는 “혹시 급하게 처리해야 할 다른 요청이 있나?” 하고 확인합니다. 마우스 움직임이나 키보드 입력 같은 긴급 신호(인터럽트)가 있다면, 하던 일을 잠시 멈추고 해당 작업을 먼저 처리하는 ‘인터럽트 사이클’로 진입하게 됩니다.
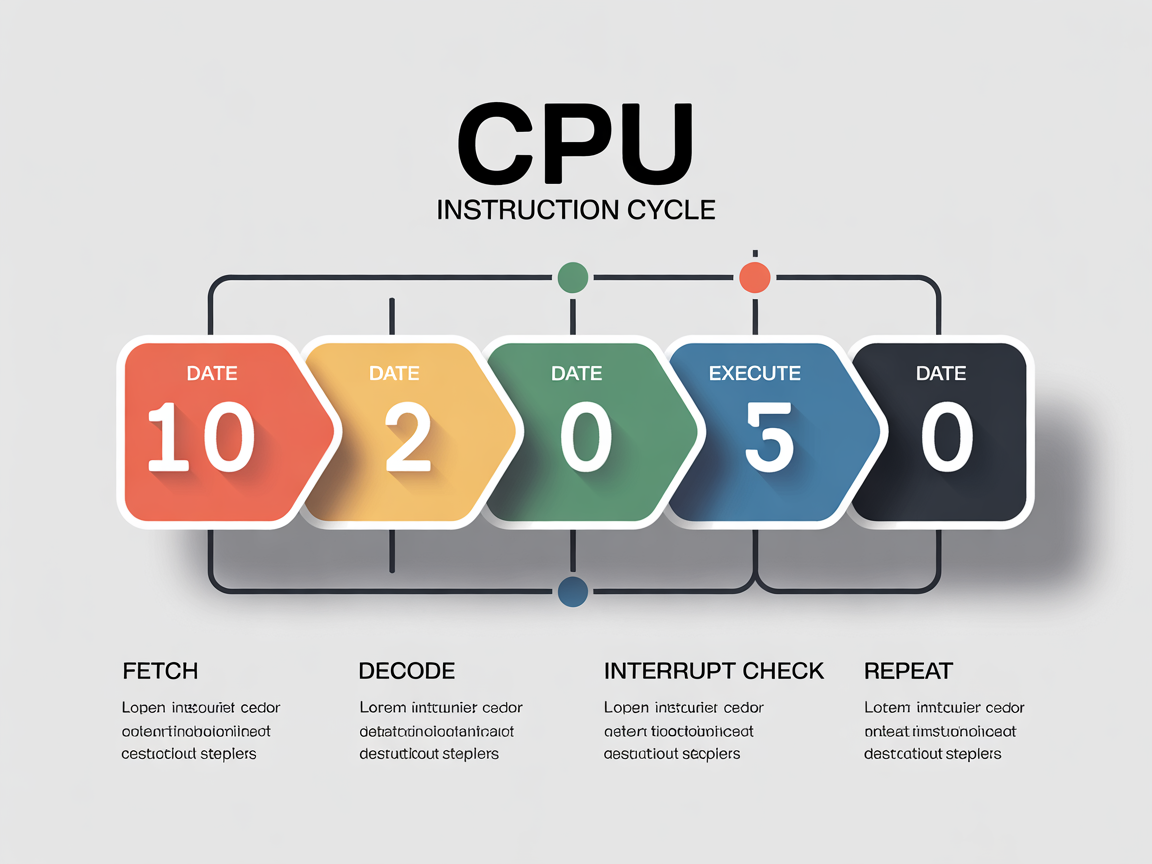
5. 전체 흐름 요약 및 시각적 정리 (Summary)
지금까지 살펴본 복잡한 과정을 한눈에 들어오도록 정리해 보겠습니다. CPU는 전원이 꺼질 때까지 아래의 과정을 무한히 반복합니다.
CPU 명령어 사이클 흐름도:
[시작]
↓
[1. 인출 (Fetch)] : 메모리에서 명령어를 가져옴 (PC -> MAR -> MBR -> IR)
↓
[2. 해석 (Decode)] : 무슨 명령어인지 분석 (Opcode/Operand 분리)
↓
[3. 실행 (Execute)] : 실제 연산 수행 (ALU 동작, 데이터 이동)
↓
[4. 인터럽트 확인] : "급한 일 있나요?" (Yes → 인터럽트 처리 / No → 계속)
↓
[반복] : 다시 1번 인출 단계로 이동
요리사 비유 최종 정리:
- 인출: 주문서(명령어)를 카운터에서 주방으로 가져옵니다.
- 해석: 메뉴가 무엇인지, 재료는 어디 있는지 조리법을 확인합니다.
- 실행: 실제로 재료를 썰고 볶아서 요리를 완성합니다.
- 반복: 다음 주문이 있는지 확인하고 다시 주문서를 가지러 갑니다.
6. 결론 (Conclusion)
우리가 컴퓨터로 즐기는 화려한 게임이나 복잡한 영상 편집도, 결국은 CPU 내부에서 일어나는 명령어 인출 과정, 해석, 실행이라는 아주 단순한 동작의 집합입니다.
2026년 현재의 고성능 CPU들은 이 과정을 더 극대화하기 위해 ‘파이프라이닝(Pipelining)’이라는 기술을 사용합니다. 앞의 명령어를 실행하는 동안, 놀지 않고 다음 명령어를 미리 인출하고 해석하는 방식이죠. 덕분에 현대의 프로세서는 초당 수십억 개의 명령어를 물 흐르듯 처리할 수 있습니다.
오늘 배운 명령어 인출 과정과 사이클의 원리는 컴퓨터 구조를 이해하는 가장 단단한 초석이 될 것입니다. 이 기초가 탄탄하다면, 앞으로 등장할 더 새로운 컴퓨터 기술도 훨씬 쉽게 이해할 수 있을 것입니다.
자주 묻는 질문 (FAQ)
Q: 레지스터가 없으면 CPU는 작동할 수 없나요?
A: 레지스터가 없다면 CPU는 모든 데이터를 메모리에서 직접 가져와야 합니다. 메모리는 CPU보다 속도가 훨씬 느리기 때문에, 레지스터라는 고속 임시 저장 공간이 없다면 컴퓨터의 처리 속도는 현저히 느려져 정상적인 작동이 어려울 것입니다.
Q: 인터럽트(Interrupt)가 발생하면 하던 일은 어떻게 되나요?
A: 인터럽트가 발생하면 CPU는 현재 실행 중인 프로그램의 상태(PC 값 등)를 스택(Stack)이라는 메모리 영역에 안전하게 저장합니다. 그 후 긴급한 작업(인터럽트)을 처리하고, 처리가 끝나면 저장해 둔 정보를 불러와 멈췄던 지점부터 다시 작업을 이어갑니다.
Q: 파이프라이닝은 모든 CPU에 적용되나요?
A: 현대에 사용되는 대부분의 고성능 프로세서(스마트폰, PC 등)에는 파이프라이닝 기술이 기본적으로 적용되어 있습니다. 이를 통해 명령어 처리 효율을 획기적으로 높이고 있습니다.