핵심 요약
- 메모리 주소는 데이터를 저장하는 1바이트 단위의 고유 식별 번호로, 컴퓨터가 데이터를 관리하는 기본 단위입니다.
- 논리 주소와 물리 주소의 차이를 이해하고, MMU를 통한 변환 과정을 아는 것이 메모리 구조 파악의 핵심입니다.
- 컴퓨터 메모리 구조는 코드, 데이터, 힙, 스택의 4가지 영역으로 나뉘며 각각 효율적인 데이터 관리를 위해 존재합니다.
- 32비트와 64비트 시스템은 주소 공간의 크기에 결정적인 차이를 만들며, 이는 사용 가능한 메모리 용량과 직결됩니다.
목차
- 1. 들어가며: 프로그램은 어디에 사는가?
- 2. 기초 다지기: 메모리 주소란 무엇인가?
- 3. 핵심 개념: 메모리 주소 공간 이해하기 (물리 vs 논리)
- 4. 구조 분석: 컴퓨터 메모리 구조의 4가지 영역
- 5. 심화: 주소 공간의 크기와 한계 (32비트 vs 64비트)
- 6. 결론 (Outro)
- 자주 묻는 질문
1. 들어가며: 프로그램은 어디에 사는가?
여러분은 코딩을 하면서 int a = 10;이라는 변수를 선언했을 때, 이 숫자가 컴퓨터 내부 정확히 어디에 저장되는지 궁금해한 적이 있나요? 혹은 프로그램이 실행될 때 운영체제(OS)가 어떻게 수많은 데이터를 서로 꼬이지 않게 관리하는지 생각해 보셨나요?
이 질문에 명쾌하게 답하기 위해서는 컴퓨터 시스템의 가장 기본이 되는 메모리 주소 공간 이해하기가 필수적입니다. 단순히 코드를 짜는 것을 넘어, 이 원리를 이해하면 개발자를 괴롭히는 ‘세그먼테이션 폴트(Segmentation Fault)’나 ‘메모리 누수(Memory Leak)’ 같은 치명적인 오류를 근본적으로 파악할 수 있습니다. 오늘은 추상적으로만 느껴졌던 주소 개념부터, 실제 프로그램이 작동하는 컴퓨터 메모리 구조까지 비전공자도 이해할 수 있도록 아주 쉽게 풀어드리겠습니다.
2. 기초 다지기: 메모리 주소란 무엇인가?
컴퓨터의 메모리(RAM)는 데이터를 저장하는 거대한 창고와 같습니다. 하지만 이 창고에 물건을 아무렇게나 던져두면 나중에 찾을 수 없겠죠? 그래서 컴퓨터는 데이터를 저장하는 가장 작은 단위인 1 바이트(Byte, 8bit) 마다 고유한 식별 번호를 붙여 관리합니다. 이것이 바로 메모리 주소란 무엇인지에 대한 핵심 정의입니다.
이해를 돕기 위해 거대한 ‘아파트 단지’를 상상해 봅시다.
- 메모리 전체: 수만 세대가 사는 아파트 단지
- 1 바이트(Byte): 각 가정이 사는 집 (호실)
- 메모리 주소: 그 집의 고유한 호수 (예: 101호, 102호…)
컴퓨터는 이 ‘호수’를 통해 데이터를 읽고 씁니다. 특이한 점은 우리가 쓰는 10진수가 아닌, 0x7ffd...와 같은 16진수를 사용한다는 점입니다. 컴퓨터 내부의 2진수(0과 1) 주소 체계는 사람이 보기에 너무 길고 복잡하기 때문에, 이를 간결하게 표현하기 위해 16진수를 표준으로 사용합니다.
💡 심화 포인트: 왜 하필 바이트 단위일까요?
컴퓨터가 비트(Bit) 단위로 주소를 할당하면 주소의 길이가 너무 길어져 관리 효율이 떨어집니다. 반대로 너무 큰 단위로 묶으면 낭비되는 공간이 생깁니다. 그래서 영문자 한 글자를 표현할 수 있는 최소 단위인 1 바이트(8비트)를 주소 할당의 기본 단위로 삼았습니다. 즉, 4GB 램을 가진 컴퓨터는 약 42억 개의 1바이트짜리 ‘방’을 가지고 있고, 각 방마다 주소 명패가 붙어있는 셈입니다.
3. 핵심 개념: 메모리 주소 공간 이해하기 (물리 vs 논리)
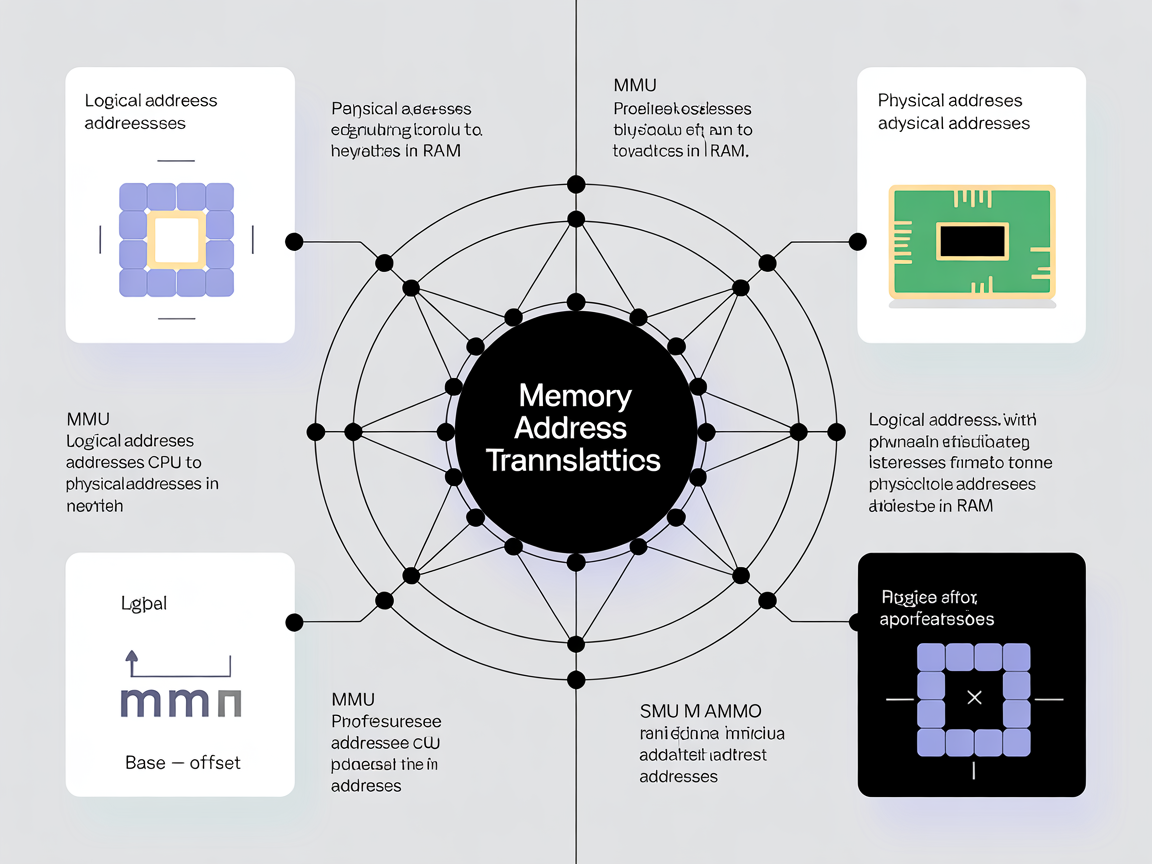
메모리 주소 공간 이해하기의 핵심은 ‘내가 보는 주소’와 ‘실제 주소’가 다르다는 점을 깨닫는 것입니다. 이를 논리 주소(Logical Address)와 물리 주소(Physical Address)라고 부릅니다.
이 두 가지 주소 체계는 컴퓨터가 여러 프로그램을 동시에 실행하면서도 서로 충돌하지 않게 만드는 비결입니다. 아래 표를 통해 차이점을 명확히 비교해 보겠습니다.
| 구분 | 설명 | 관점 | 특징 |
|---|---|---|---|
| 물리 주소 | 실제 하드웨어 RAM에 존재하는 절대적인 위치 번호입니다. | 하드웨어 관점 | 실제로 데이터가 전기신호로 저장되는 곳입니다. |
| 논리 주소 | 실행 중인 프로그램(프로세스)이 독자적으로 가진다고 착각하는 가상의 주소입니다. | 소프트웨어 관점 | 모든 프로그램은 자신이 0번지부터 시작한다고 생각합니다. |
그렇다면 가짜 주소(논리)를 어떻게 진짜 주소(물리)로 바꿀까요?
여기서 MMU(Memory Management Unit)라는 하드웨어가 등장합니다. MMU는 CPU와 메모리 사이에 위치한 ‘실시간 통역사’입니다. CPU가 “논리 주소 100번에 데이터 저장해!”라고 명령하면, MMU는 이를 낚아채 “실제로는 물리 주소 5000번입니다”라고 순식간에 변환하여 메모리에 전달합니다.
- 변환 공식:
물리 주소 = 논리 주소 + 기준 레지스터(Base Register) 값
💡 심화 포인트: 왜 이렇게 복잡하게 나눌까요?
가장 큰 이유는 보호(Protection) 때문입니다. 만약 모든 프로그램이 물리 주소에 직접 접근한다면, 악성 프로그램이 다른 프로그램이나 운영체제의 중요 데이터를 덮어쓸 수 있습니다. 하지만 가상 주소 공간을 사용하면, 각 프로그램은 부여받은 공간 외에는 절대 접근할 수 없습니다. 이로 인해 현대의 다중 프로그래밍 환경(Multi-programming)이 안전하게 유지될 수 있는 것입니다.
4. 구조 분석: 컴퓨터 메모리 구조의 4가지 영역
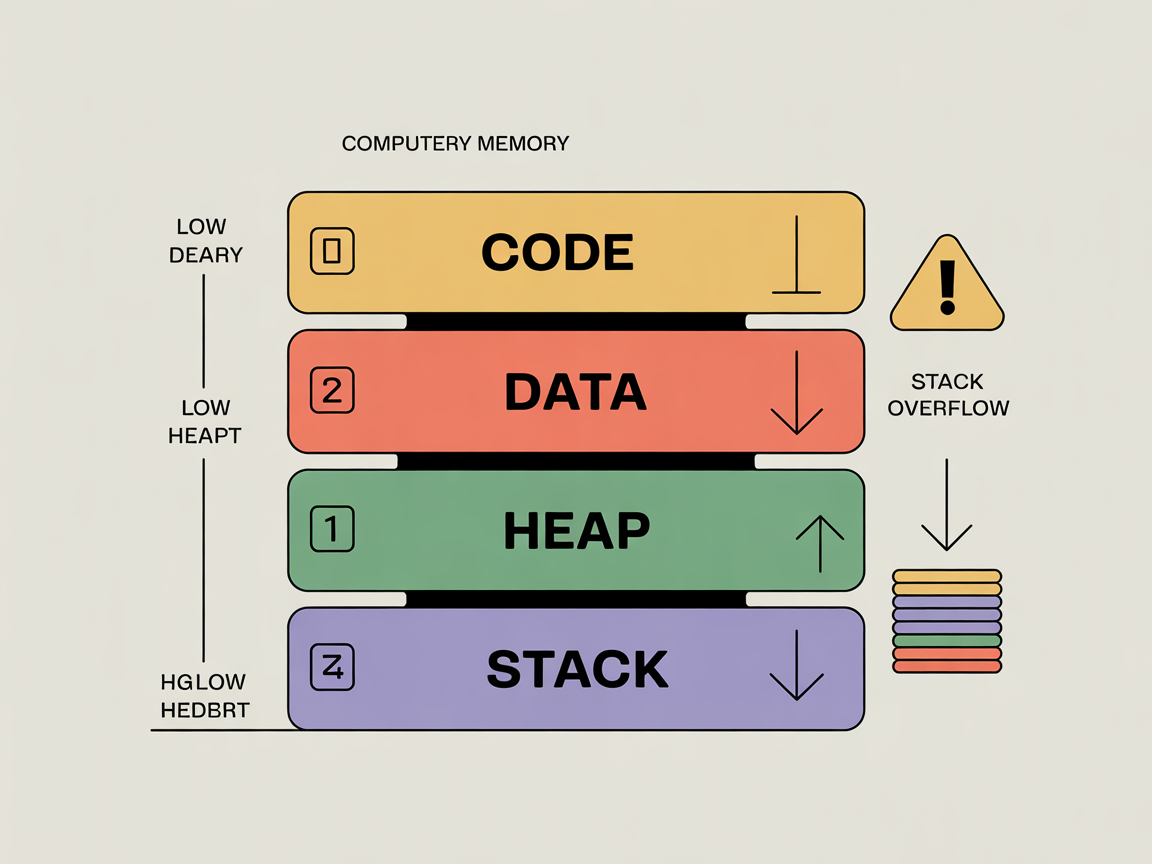
프로그램이 실행되어 메모리에 로드(Load)될 때, 운영체제는 효율적인 관리를 위해 공간을 크게 네 가지 구획으로 나눕니다. 이를 컴퓨터 메모리 구조 혹은 ‘메모리 레이아웃’이라고 합니다.
이 구조는 보통 직사각형 형태로 표현되며, 주소의 높낮이에 따라 다음과 같이 배치됩니다.
- 코드(Code) 영역 (가장 낮은 주소)
- 우리가 작성한 코드가 기계어 명령어로 변환되어 저장되는 곳입니다.
- 프로그램이 실행되는 도중에 코드가 바뀌면 안 되므로 읽기 전용(Read-Only) 속성을 가집니다.
- 데이터(Data) 영역
- 전역 변수(Global Variable)와 정적 변수(Static Variable)가 저장됩니다.
- 프로그램이 시작될 때 할당되고, 프로그램이 종료될 때까지 메모리에 남아있습니다.
- 힙(Heap) 영역
- 사용자가 필요에 따라 직접 관리하는 공간입니다. C언어의
malloc이나 Java, C++의new를 사용할 때 할당됩니다. - 낮은 주소에서 높은 주소 방향으로 공간이 커집니다.
- 사용 후 반드시 해제(Free)해주어야 하며, 그렇지 않으면 ‘메모리 누수’가 발생합니다.
- 사용자가 필요에 따라 직접 관리하는 공간입니다. C언어의
- 스택(Stack) 영역 (높은 주소)
- 함수의 지역 변수, 매개 변수, 리턴 주소가 저장되는 임시 공간입니다.
- 함수 호출이 끝나면 자동으로 사라집니다.
- 높은 주소에서 낮은 주소 방향으로 공간이 커집니다.
💡 심화 포인트: 힙과 스택의 충돌, 오버플로우(Overflow)
재미있는 점은 힙은 위로 자라고, 스택은 아래로 자란다는 것입니다. 두 영역은 같은 자유 공간(Free Space)을 공유합니다. 만약 재귀 함수를 너무 많이 호출해 스택이 계속 커지다가 힙 영역을 침범하면 스택 오버플로우(Stack Overflow)가 발생합니다. 반대의 경우는 힙 오버플로우가 됩니다. 개발자는 이 두 영역의 ‘영토 분쟁’이 일어나지 않도록 메모리 사용량을 적절히 관리해야 합니다.
5. 심화: 주소 공간의 크기와 한계 (32비트 vs 64비트)
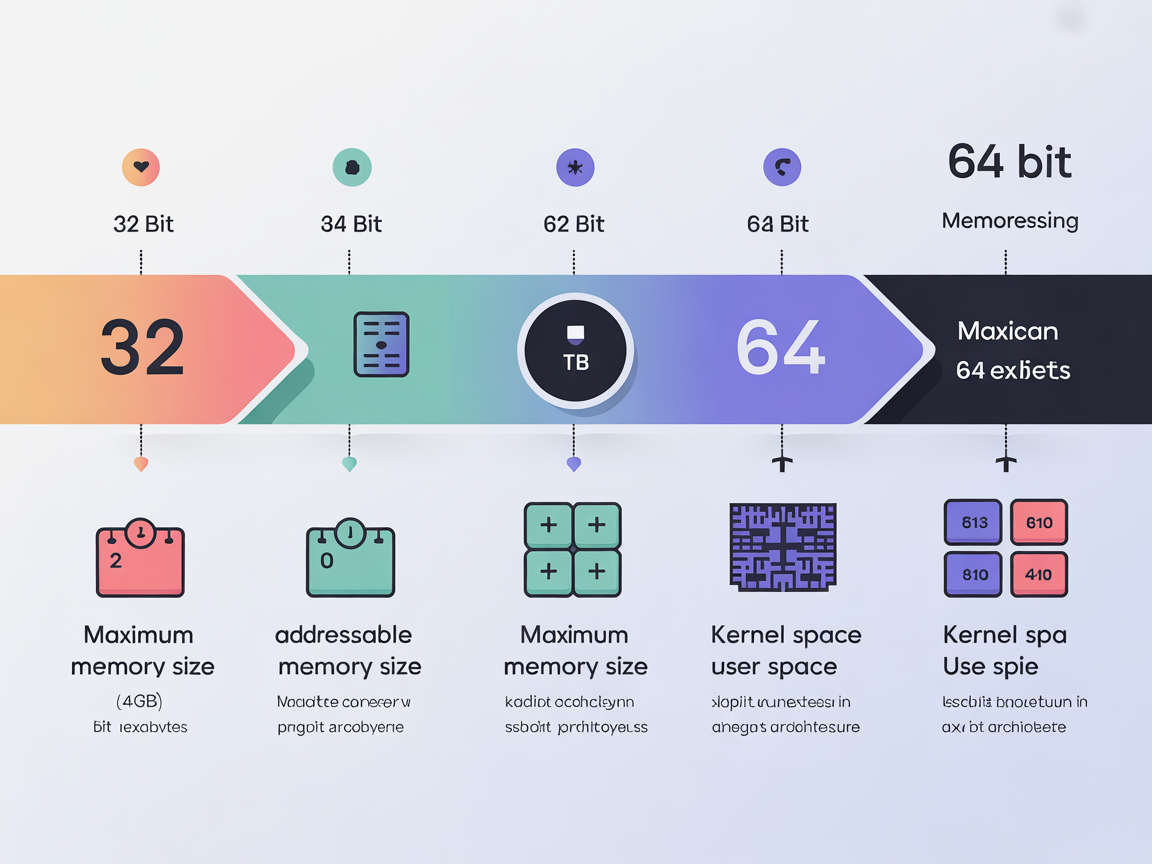
2026년 현재 우리는 64비트 시스템을 표준으로 사용하고 있지만, 불과 십수 년 전만 해도 32비트가 주류였습니다. 이 비트 수는 CPU가 한 번에 처리할 수 있는 데이터의 크기이자, 가질 수 있는 주소 공간의 크기를 결정합니다.
- 32비트 시스템의 한계: 주소를 232개, 즉 약 42억 개까지만 만들 수 있습니다. 이는 최대 4GB의 메모리만 인식할 수 있다는 뜻입니다. 램을 16GB를 꽂아도 4GB밖에 못 쓰는 답답한 상황이 발생했었죠.
- 64비트 시스템의 혁명: 주소를 264개까지 만들 수 있습니다. 이는 약 16 엑사바이트(EB)라는 천문학적인 크기입니다. 현재 전 세계의 데이터를 다 합쳐도 담을 수 있을 만큼 광활한 가상 주소 공간을 제공합니다.
또한, 이 거대한 주소 공간은 다시 커널 공간(Kernel Space)과 사용자 공간(User Space)으로 나뉩니다. 메모리의 최상위 영역은 운영체제 핵심부인 커널만 사용할 수 있도록 철저히 격리되어 있습니다. 사용자가 작성한 프로그램이 실수로 운영체제의 영역을 건드려 시스템을 다운시키는 것을 막기 위한 보안 장치입니다.
💡 심화 포인트: 램이 16GB인데 어떻게 더 큰 프로그램을 돌릴까요?
64비트 시스템의 가상 주소 공간은 엄청나게 크지만, 실제 물리적 RAM(예: 16GB, 32GB)은 그보다 훨씬 작습니다. 이때 운영체제는 스와핑(Swapping) 기술을 사용합니다. 당장 쓰지 않는 데이터를 RAM에서 SSD(디스크)로 잠시 옮겨두고, 빈 공간에 필요한 데이터를 불러오는 방식입니다. 덕분에 우리는 물리 메모리 크기보다 훨씬 큰 대용량 프로그램도 문제없이 실행할 수 있습니다.
6. 결론 (Outro)
지금까지 메모리 주소 공간 이해하기를 주제로 주소의 정의부터 컴퓨터 메모리 구조의 상세 영역, 그리고 64비트 시스템의 특징까지 살펴보았습니다.
오늘 배운 내용을 요약하면 다음과 같습니다.
- 메모리 주소는 바이트 단위로 부여된 데이터의 위치 식별자입니다.
- 우리는 논리 주소를 통해 프로그래밍하며, MMU가 이를 실제 물리 주소로 변환해 줍니다.
- 메모리는 코드, 데이터, 힙, 스택 4가지 영역으로 나뉘어 효율적으로 관리됩니다.
C언어의 포인터가 어렵게 느껴지거나 프로그램이 이유 없이 종료될 때, 오늘 머릿속에 그린 이 ‘메모리 지도’를 떠올려 보세요. 데이터가 어디서 와서 어디로 가는지, 흐름이 훨씬 명확하게 보일 것입니다. 기본기가 탄탄한 개발자는 어떤 복잡한 버그 앞에서도 당황하지 않습니다.
자주 묻는 질문
Q: 메모리 주소는 왜 16진수를 사용하나요?
A: 컴퓨터 내부에서는 2진수를 사용하지만, 주소 길이가 너무 길어집니다. 이를 사람이 이해하기 쉽고 간결하게 표현하기 위해 2진수 4자리를 하나로 묶을 수 있는 16진수를 표준으로 사용합니다.
Q: 스택 오버플로우와 메모리 누수의 차이는 무엇인가요?
A: 스택 오버플로우는 스택 영역이 힙 영역을 침범할 정도로 넘쳤을 때 발생하는 오류이며, 메모리 누수는 힙 영역에서 빌린 메모리를 반납하지 않아 사용 가능한 메모리가 줄어드는 현상입니다.
Q: 64비트 컴퓨터에서는 메모리 부족 현상이 없나요?
A: 가상 주소 공간은 거의 무한대에 가깝지만, 실제 물리적인 RAM 용량은 한계가 있습니다. 따라서 너무 많은 프로그램을 동시에 실행하면 스와핑 과정에서 속도가 느려지거나 물리 메모리 부족 현상을 겪을 수 있습니다.