핵심 요약
- 명령어 병렬 처리 기법(ILP)은 클럭 속도 경쟁의 물리적 한계를 극복하고 단일 코어의 효율성을 극대화하는 핵심 기술입니다.
- 단일 코어 내부에서 파이프라이닝, 슈퍼스칼라, 비순차 실행 등의 기법을 통해 동시에 여러 명령어를 처리합니다.
- 데이터, 구조적, 제어 해저드(Hazard)를 극복하기 위해 분기 예측과 전방 전달 같은 정교한 메커니즘이 사용됩니다.
- 개발자는 이러한 하드웨어 원리를 이해함으로써 시스템 최적화와 효율적인 소프트웨어 설계의 통찰을 얻을 수 있습니다.
목차
- 서론: CPU 속도의 한계와 돌파구
- 병렬 처리의 기초와 종류 (배경 지식)
- 핵심 개념: 명령어 레벨 병렬성(ILP)이란?
- 주요 명령어 병렬 처리 기법 상세 분석
- 병렬 처리의 장애물: 해저드(Hazard)
- 결론: ILP의 현재와 미래
- 자주 묻는 질문
1. 서론: CPU 속도의 한계와 돌파구
2000년대 초반, 전 세계 PC 시장은 그야말로 ‘속도 전쟁’ 중이었습니다. 1GHz를 넘어 2GHz, 3GHz, 4GHz까지, CPU 제조사들은 클럭 속도(Clock Speed)를 높이는 데 사활을 걸었죠. 하지만 2026년 현재, 우리는 더 이상 클럭 속도만으로 CPU의 성능을 판단하지 않습니다. 왜 그럴까요? 무작정 속도만 높이다가는 엄청난 발열과 전력 소모라는 물리적 한계에 부딪히기 때문입니다. 소위 말하는 ‘발열 지옥’이 기다리고 있었던 것이죠.
그렇다면 현대의 고성능 프로세서는 어떻게 성능을 비약적으로 발전시켰을까요? 그 비결은 ‘얼마나 빨리’ 처리하느냐가 아니라, ‘얼마나 효율적으로 동시에’ 처리하느냐에 있습니다. 과거에는 한 번에 하나씩 일을 빠르게 처리하려고 애썼다면, 지금은 한 번에 여러 가지 일을 동시에 처리하는 스마트한 방식을 택한 것입니다.
이러한 효율성의 정점에 있는 기술이 바로 오늘 소개할 명령어 병렬 처리 기법입니다. CPU 내부에서 마법처럼 시간을 쪼개고 늘려 성능을 극대화하는 이 기술은, 오늘날 우리가 사용하는 스마트폰부터 슈퍼컴퓨터까지 모든 컴퓨팅 파워의 근간이 됩니다. 이 글을 통해 명령어 병렬 처리 기법이 어떻게 CPU를 쉬지 않고 일하게 만드는지, 그 정교한 메커니즘을 파헤쳐 보겠습니다.
2. 병렬 처리의 기초와 종류 (배경 지식)
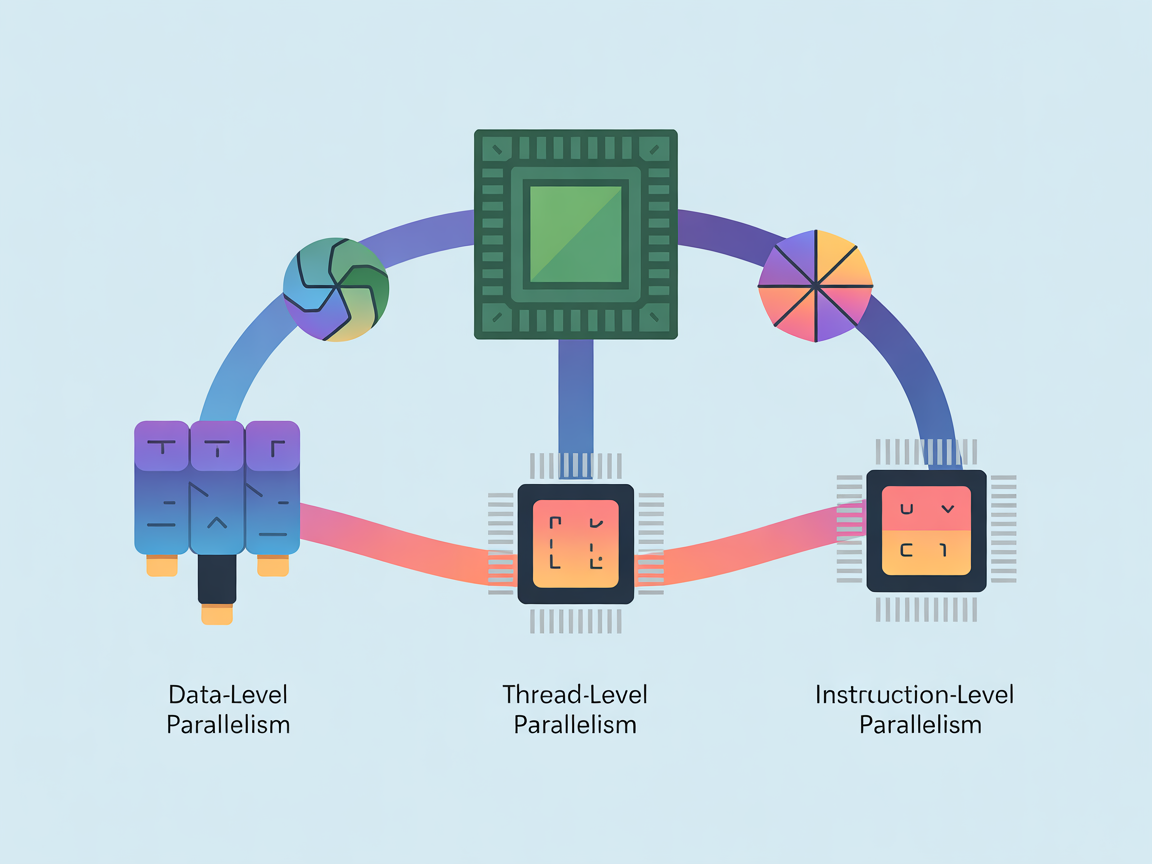
본격적인 내용에 앞서, ‘병렬 처리(Parallel Processing)’가 무엇인지, 그리고 어떤 레벨에서 이루어지는지 간단히 짚고 넘어갈 필요가 있습니다. 병렬 처리는 말 그대로 여러 작업을 동시에 수행하여 전체 처리 시간을 단축하는 기술을 말합니다. 컴퓨터 구조에서는 크게 세 가지 단계로 나눕니다.
1. 데이터 레벨 병렬성 (Data-Level Parallelism, DLP)
가장 직관적인 형태입니다. “벡터 프로세서”나 우리가 흔히 쓰는 GPU(그래픽 카드)가 대표적인 예입니다. 예를 들어 이미지의 밝기를 조절할 때, 픽셀 하나하나를 순서대로 계산하는 것이 아니라 수천 개의 픽셀 데이터에 동시에 똑같은 명령을 내려 처리합니다. ‘하나의 명령어’로 ‘다량의 데이터’를 한 번에(SIMD) 처리하는 방식이죠.
2. 스레드 레벨 병렬성 (Thread-Level Parallelism, TLP)
우리가 흔히 “쿼드 코어”, “옥타 코어”라고 부르는 멀티 코어 CPU 환경에서 일어나는 병렬성입니다. 웹 브라우저를 켜두고 동시에 게임을 돌릴 수 있는 것처럼, 물리적으로 여러 개의 코어가 각각 다른 프로그램(스레드)을 맡아 동시에 실행하는 방식입니다.
3. 명령어 레벨 병렬성 (Instruction-Level Parallelism, ILP)
오늘 우리가 깊게 다룰 핵심 주제입니다. 앞서 말한 TLP가 ‘여러 코어’를 쓰는 것이라면, ILP는 ‘하나의 코어’ 안에서 일어나는 병렬 처리입니다. 단일 코어 내부에서 실행해야 할 명령어들을 아주 잘게 쪼개고, 순서를 재배치하여 마치 동시에 여러 명령어가 실행되는 것처럼 만드는 고도의 기술입니다.
병렬 처리 종류를 이해하는 것은 현대 컴퓨터 아키텍처를 이해하는 첫걸음입니다. 지금부터는 단일 코어의 성능을 극한으로 끌어올리는 명령어 병렬 처리 기법, 즉 ILP의 세계로 들어가 보겠습니다.
3. 핵심 개념: 명령어 레벨 병렬성(ILP)이란?
명령어 레벨 병렬성(Instruction-level Parallelism, ILP)의 궁극적인 목표는 단순합니다. “CPU가 단 0.0001초도 놀지 않게 하라!”입니다.
전문 용어로는 CPI(Cycles Per Instruction)를 1 미만으로 낮추는 것이 목표라고 합니다. CPI가 1이라는 건 한 번의 클럭 사이클(Tick)에 명령어 하나를 처리한다는 뜻인데, ILP 기술을 적용하면 한 번의 사이클에 2개, 3개, 혹은 그 이상의 명령어를 동시에 처리할 수 있게 됩니다.
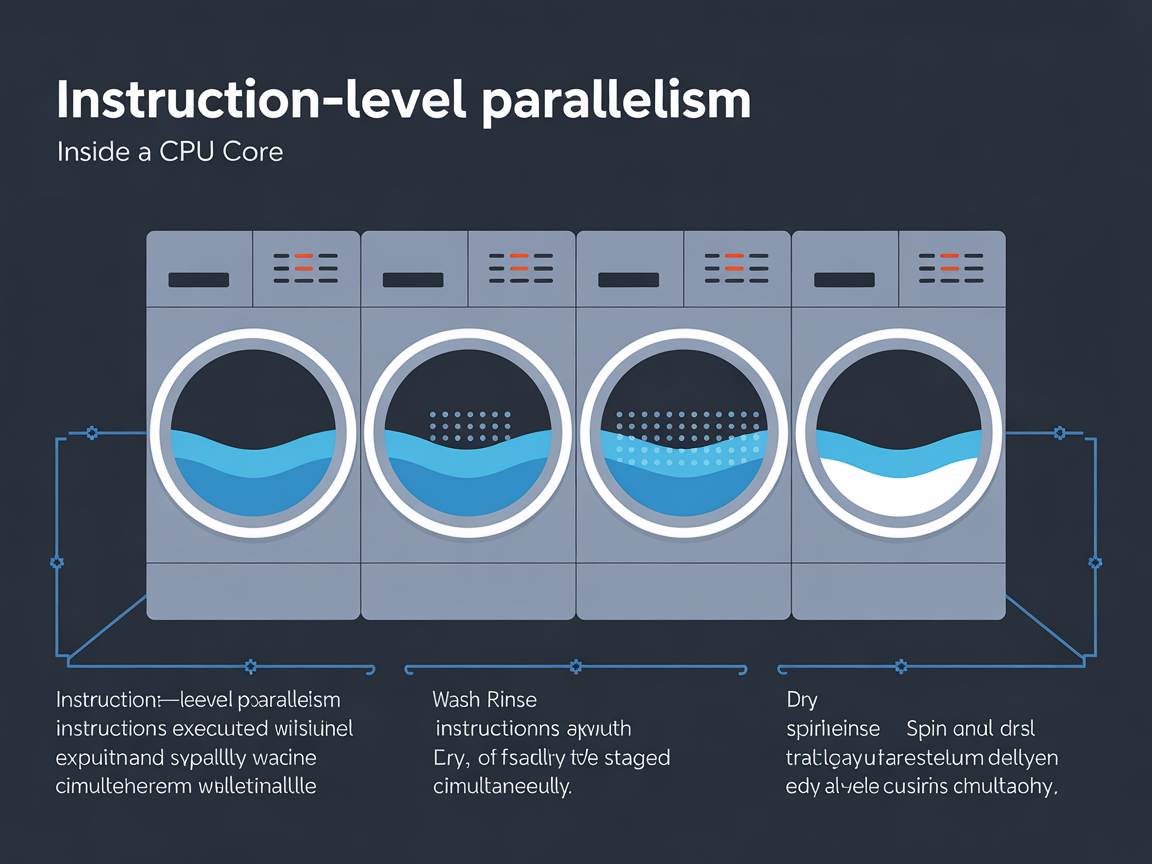
🧺 세탁기로 이해하는 ILP의 원리
이 개념이 어렵다면 ‘빨래’를 떠올려보세요. 빨래는 보통 세탁 -> 헹굼 -> 탈수 -> 건조의 4단계를 거칩니다.
- 순차 처리 방식: A의 빨래가 세탁부터 건조까지 완전히 다 끝난 뒤에야 B가 세탁기를 돌릴 수 있습니다. 매우 비효율적이죠.
- ILP (파이프라인) 방식: A의 빨래가 ‘헹굼’ 단계로 넘어가면, 세탁통은 비게 됩니다. 이때 놀리지 않고 바로 B의 빨래를 넣어 ‘세탁’을 시작하는 것입니다. 이렇게 되면 A가 건조할 때 B는 탈수, C는 헹굼, D는 세탁을 동시에 진행할 수 있습니다.
이처럼 명령어 병렬 처리 기법은 CPU 내부의 자원이 쉴 틈을 주지 않고 빽빽하게 작업을 밀어 넣어, 결과적으로 단위 시간당 처리량을 극대화하는 기술입니다.
4. 주요 명령어 병렬 처리 기법 상세 분석
그렇다면 CPU 설계자들은 구체적으로 어떤 마법을 부려 이 병렬성을 구현했을까요? 현대 프로세서에 적용된 핵심 기법 5가지를 상세히 분석해 봅니다.
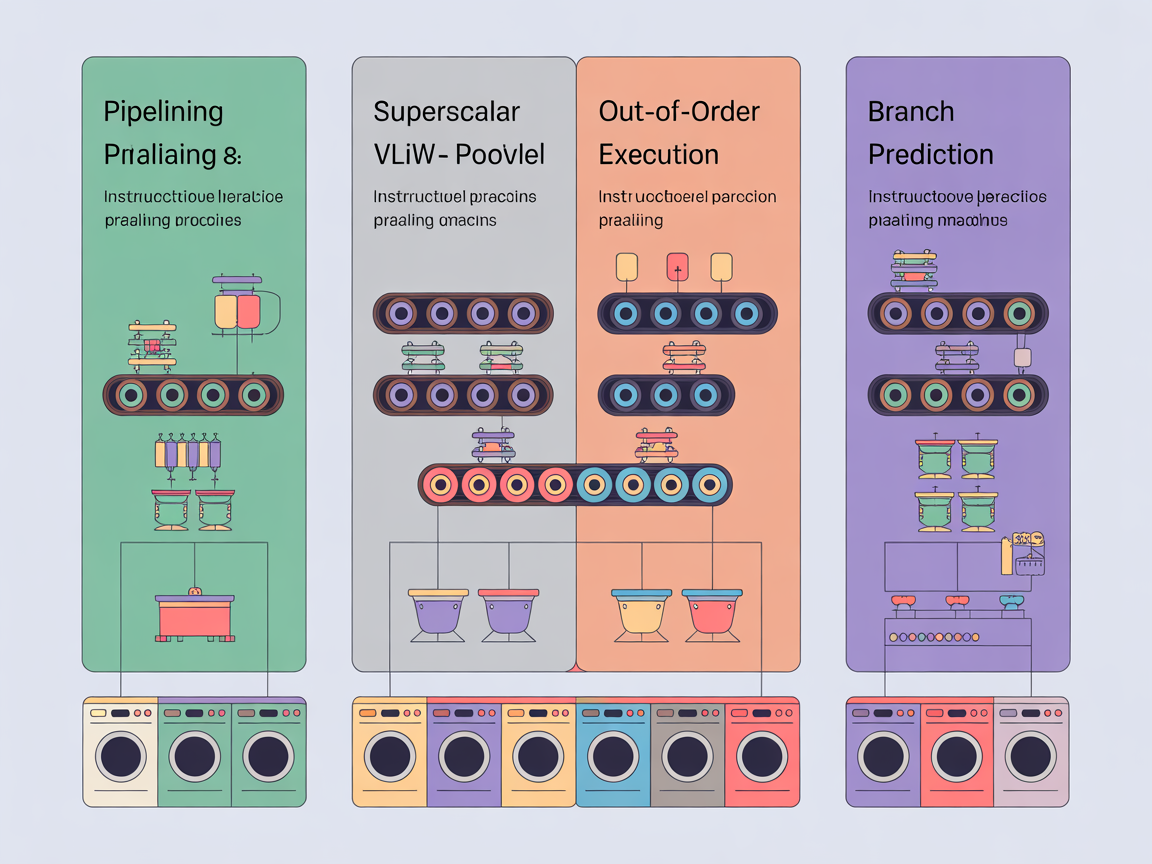
1. 파이프라이닝 (Pipelining)
가장 기본이 되는 명령어 병렬 처리 기법입니다. CPU가 명령어를 처리하는 과정을 보통
4~5단계(인출(Fetch) → 해석(Decode) → 실행(Execute) → 메모리(Memory) → 저장(Write-back))로 잘게 나눕니다. 그리고 앞서 설명한 세탁기
예시처럼, 첫 번째 명령어가 ‘해석’ 단계로 넘어가면 즉시 두 번째 명령어를 ‘인출’합니다. 공장의 컨베이어 벨트 시스템을 CPU 안에 구현한 것이라고 보면 됩니다.
- 시공간 다이어그램(Time-Space Diagram) 묘사: 시간 축(x축)을 따라갈 때, 계단식으로 명령어들이 겹쳐서 실행되는 모습을 상상해 보세요. 파이프라이닝이 없다면 막대그래프가 하나 끝나고 다음 것이 나오지만, 파이프라이닝 환경에서는 막대들이 사선으로 겹쳐지며 빈틈없이 꽉 채워집니다.
2. 슈퍼스칼라 (Superscalar)
“파이프라인 하나로는 부족해!”라는 생각에서 나온 기술입니다. 파이프라인 라인 자체를 여러 개(복수)로 두는 것입니다.
- 작동 원리: 한 번의 클럭 사이클에 명령어를 2개, 3개씩 동시에 인출하고 실행합니다. 마치 세탁기를 2대, 3대 놓고 동시에 돌리는 것과 같습니다.
- 특징: 현대의 인텔 코어(Intel Core)나 AMD 라이젠(Ryzen) 등 대부분의 고성능 CPU는 이 슈퍼스칼라 구조를 채택하고 있습니다. 하드웨어가 매우 복잡해지지만 성능 향상 폭이 큽니다.
3. VLIW (Very Long Instruction Word)
슈퍼스칼라가 하드웨어의 힘으로 동시에 실행할 명령어를 찾았다면, VLIW는 ‘소프트웨어(컴파일러)’에게 그 짐을 맡깁니다.
- 작동 원리: 컴파일러가 프로그램을 번역할 때, “아, 이 명령어들은 서로 관련이 없으니 동시에 실행해도 되겠다”라고 미리 판단합니다. 그리고 이것들을 묶어서 아주 긴 하나의 명령어(Very Long Instruction)로 만들어 CPU에 던져줍니다.
- 장점: CPU 내부 구조가 단순해져 전력 소모를 줄일 수 있습니다. (주로 임베디드나 DSP 분야에서 활용)
4. 비순차 실행 (Out-of-Order Execution, OoOE)
명령어가 들어온 순서대로만 처리하다 보면, 앞선 작업이 늦어질 때 뒤의 작업들도 줄줄이 기다려야 하는 상황(병목 현상)이 생깁니다.
- 해결책: CPU가 능동적으로 순서를 바꿉니다! “어? 3번 명령어는 1번, 2번 결과랑 상관없네? 재료도 다 있네? 그럼 먼저 실행해!”라며 새치기를 허용하는 기술입니다. 이를 통해 파이프라인이 멈추는 것(Stall)을 막습니다.
5. 분기 예측 (Branch Prediction)
프로그램에는 if (조건) { ... } else { ... }와 같은 분기문이 수시로 등장합니다. 조건 계산이 끝날 때까지 멍하니 기다리면 손해가 큽니다.
- 작동 원리: CPU가 과거의 기록을 바탕으로 “이번에도 참(True)일 확률이 높아!”라고 예측하고, 미리 그쪽 경로의 명령어를 가져와 실행해 버립니다.
- 투기적 실행: 만약 예측이 맞으면 대박(성능 향상), 틀리면 미리 한 작업을 다 취소하고 다시 하면 됩니다. 현대 CPU의 예측 적중률은 90%가 넘을 정도로 정교합니다.
[요약 비교: 주요 병렬 처리 기법]
| 기법 | 핵심 메커니즘 | 비유 | 장점 |
|---|---|---|---|
| 파이프라이닝 | 명령어 단계 중첩 | 컨베이어 벨트 | 기본 성능 효율 증대 |
| 슈퍼스칼라 | 다중 파이프라인 | 세탁기 여러 대 동시 가동 | 처리량(Throughput) 대폭 향상 |
| VLIW | 컴파일러가 묶어서 처리 | 미리 묶음 배송 | 하드웨어 구조 단순화 |
| 비순차 실행 | 실행 순서 동적 변경 | 순서 상관없이 재료 있는 요리부터 하기 | 파이프라인 멈춤(Stall) 최소화 |
5. 병렬 처리의 장애물: 해저드(Hazard)
물론 명령어 병렬 처리 기법이 만능은 아닙니다. 파이프라인을 쌩쌩 돌리고 싶어도 어쩔 수 없이 멈춰야 하는 상황이 발생하는데, 이를 해저드(Hazard)라고 부릅니다. 크게 세 가지 악당이 있습니다.
1. 구조적 해저드 (Structural Hazard)
두 명의 요리사가 동시에 하나의 칼을 쓰려고 할 때 발생하는 문제입니다. 즉, 여러 명령어가 동시에 실행되면서 같은 하드웨어 자원(ALU, 레지스터, 메모리 포트 등)을 쓰려고 충돌할 때 발생합니다. 자원을 추가하거나 순서를 미뤄서 해결합니다.
2. 데이터 해저드 (Data Hazard)
앞 명령어가 싼 똥(?)을 뒤 명령어가 치워야 하는데, 아직 안 싼 상황입니다. 즉, 데이터 의존성 문제입니다.
- RAW (Read After Write): 가장 흔한 문제입니다. 앞 명령어가 계산한 값(
x = 1 + 2)을 뒤 명령어(y = x + 3)가 써야 하는데,x값이 아직 저장이 안 된 상태에서 읽으려 할 때 발생합니다. - 해결책: 전방 전달(Forwarding)이라는 기술을 씁니다. 저장 단계까지 기다리지 않고, 연산이 끝나자마자 결과값을 바로 다음 명령어에게 던져주는 방식입니다.
3. 제어 해저드 (Control Hazard)
앞서 말한 if 문이나 jump 명령처럼, 다음에 실행할 주소가 갑자기 바뀌는 경우입니다. 파이프라인에는 이미 다음 명령어들을 잔뜩 줄 세워 놨는데, 갑자기
“어? 이 길이 아니네?” 하고 엉뚱한 곳으로 점프해야 하면, 미리 줄 세운 명령어들을 다 버려야 합니다. 이를 해결하기 위해 분기 예측을 사용합니다.
if (condition) {
// 분기 예측이 필요한 영역
execute_path_A();
} else {
execute_path_B();
}

6. 결론: ILP의 현재와 미래
지금까지 CPU 내부의 치열한 효율성 전쟁, 명령어 병렬 처리 기법에 대해 알아보았습니다.
과거에는 클럭 속도를 높이는 것이 최고였지만, 이제는 파이프라이닝, 슈퍼스칼라, 비순차 실행과 같은 고도화된 ILP 기술들이 CPU 성능을 지탱하고 있습니다. 이러한 기술들이 층층이 쌓여 온 덕분에 우리는 손바닥만한 스마트폰으로도 고사양 게임과 복잡한 연산을 끊김 없이 즐길 수 있게 된 것입니다.
물론 2026년 현재, ILP 기술만으로는 성능 향상에 한계가 있어 멀티 코어(TLP)나 AI 전용 가속기(NPU) 같은 이기종 컴퓨팅이 대세가 되었습니다. 하지만 단일 코어(Single Core)의 성능 최적화는 여전히 모든 컴퓨팅의 기초 체력입니다. 그 기초 체력을 기르는 핵심 비법이 바로 ILP인 셈입니다.
하드웨어가 어떻게 동작하는지 이해하는 것은 개발자에게 큰 무기가 됩니다. 단순히 코드를 짜는 것을 넘어, 내 코드가 CPU 안에서 어떻게 쪼개지고 병렬로 실행되는지 상상할 수 있다면, 더 효율적이고 강력한 소프트웨어를 설계할 수 있을 것입니다. 명령어 레벨 병렬성(ILP), 보이지 않는 곳에서 끊임없이 달리는 CPU의 노력을 기억해 주세요.
자주 묻는 질문 (FAQ)
Q1. 명령어 병렬 처리(ILP)와 멀티 코어(TLP)는 같은 것인가요?
A. 아닙니다. ILP는 하나의 코어 안에서 명령어를 동시에 처리하는 기술이고, TLP는 여러 개의 코어가 각각 다른 작업을 수행하는 기술입니다. 현대 CPU는 두 가지를 모두 사용합니다.
Q2. 분기 예측이 틀리면 어떻게 되나요?
A. 예측이 틀릴 경우, 미리 수행했던 작업(투기적 실행)을 모두 취소하고 올바른 경로의 명령어를 다시 가져와야 합니다. 이를 ‘플러시(Flush)’라고 하며, 이때 성능 손실(페널티)이 발생합니다.
Q3. 프로그래머가 ILP를 직접 제어할 수 있나요?
A. 대부분은 하드웨어와 컴파일러가 알아서 처리합니다. 하지만 데이터 의존성을 줄이거나 분기문을 효율적으로 작성하는 등 코드를 최적화하면 컴파일러가 ILP를 더 잘 활용하도록 도울 수 있습니다.