핵심 요약
- MySQL 학습 로드맵은 IT 초보자가 “설치 → 문법 → 관계형 사고 → 실전” 흐름으로 데이터베이스를 체계적으로 정복하기 위한 5단계 가이드입니다.
- GUI 툴 + CRUD로 시작하되, 중간부터는 CLI(터미널)도 함께 익혀야 실전에서 막히지 않습니다.
- JOIN + 정규화 + 키(PK/FK)를 이해하면 “테이블이 왜 여러 개인지”가 보이고, 관계형 DB의 핵심 감각이 생깁니다.
- 성능 최적화(EXPLAIN/인덱스) + 실전 프로젝트까지 가면 “조회”를 넘어 “시스템 관점”으로 데이터를 다루는 기본 역량이 완성됩니다.
목차
- 도입부: 데이터 중심 시대의 필수 생존 기술
- Step 1: 환경 설정과 기본 개념 (두려움 없애기)
- Step 2: SQL 기본 문법 (CRUD) 익히기
- Step 2.5: 테이블 설계·데이터 타입·제약조건 (진짜 기초 체력)
- Step 3: 데이터 연결과 구조의 이해 (관계형 DB의 꽃)
- Step 4: 중급 도약 – 함수와 서브쿼리
- Step 5: 성능 최적화와 고급 기능 (Advanced)
- 효율적인 학습 방법론 (How to Study)
- 결론
- 자주 묻는 질문 (FAQ)
도입부
MySQL 학습 순서, 어디서부터 시작해야 할지 막막한 IT 초보자분들을 위해 가장 효율적인 로드맵을 정리했습니다.
지금 이 순간에도 당신의 스마트폰 속에서는 수많은 데이터가 움직이고 있습니다. 유튜브 검색 기록, 어젯밤 주문한 배달 앱의 내역, 매달 빠져나가는 넷플릭스 결제 정보까지 — 이 모든 정보가 데이터베이스(Database)라는 거대한 창고에 저장되고 관리됩니다. “데이터 중심(Data-Driven)” 시대, 이제 데이터베이스를 다루는 능력은 개발자만의 전유물이 아닙니다. 마케터는 고객 데이터를 분석해 타겟을 정하고, 기획자는 서비스 지표를 조회해 개선점을 찾습니다.
하지만 많은 분이 막상 공부를 시작하려다 ‘검은 화면(CLI)’과 복잡한 영어 명령어에 겁을 먹고 포기합니다. “설치하다 에러 나서 그만뒀어요”라는 하소연도 심심찮게 들립니다. 걱정하지 마세요. 세계에서 가장 인기 있는 오픈소스 데이터베이스인 MySQL을 통해, 누구나 따라 할 수 있는 IT 초보 MySQL 공부법을 알려드리겠습니다. 암기 대신 흐름을 이해하는 로드맵만 따라오시면, 여러분도 데이터를 다루는 실무 기초를 마스터할 수 있습니다.
Step 1: 환경 설정과 기본 개념 (두려움 없애기)
데이터베이스 공부 방법의 첫걸음은 “쉽고 편한 환경”을 만드는 것입니다. 처음부터 어려운 설정과 씨름하면 금방 지치기 때문에, 일단 접속 성공 + 실습 환경 준비가 목표입니다.
1. 데이터베이스(DB) vs DBMS: 도서관과 사서
먼저 개념부터 확실히 잡고 갑시다.
- 데이터베이스(DB): 책이 가득 꽂혀 있는 ‘도서관’입니다. 데이터가 저장된 공간(데이터의 집합)이죠.
- DBMS (Database Management System): 책을 정리하고 찾아주는 ‘사서’입니다. 우리는 사서(DBMS)에게 “이 책 찾아줘”라고 요청하면 됩니다. MySQL이 바로 이 역할을 하는 DBMS입니다.
2. 설치는 GUI로 시작하되, CLI도 곧 익히게 됩니다
처음에는 클릭으로 조작하는 GUI(Graphic User Interface) 툴이 심리적으로 편합니다. 다만 실전에서는 CLI도 필요해지므로, Step 2부터는 GUI + CLI 병행을 목표로 잡는 것이 좋습니다.
- MySQL Workbench: MySQL 공식 툴로, 가장 안정적이고 기능이 강력합니다. 초보자에게 적극 추천합니다.
- DBeaver: 여러 종류의 DB(Oracle, PostgreSQL 등)를 한 번에 관리할 수 있어 실무에서 인기가 높습니다.
[입문자 제안]
Docker로 한 줄 설치도 가능하지만, 입문자라면 먼저 Workbench 설치 + 로컬 접속 성공을 권장합니다. 설치 후에는 텅 빈 공간에 연습할 데이터를 채워 넣어야 합니다. MySQL 샘플 DB인Sakila(영화 대여점 데이터)나Employees(직원 관리 데이터)를 불러오면, 실제 서비스 같은 환경에서 바로 실습을 시작할 수 있습니다.
[부가 설명] 설치 과정에서 Root Password를 설정하는 단계가 나옵니다. 이 비밀번호는 데이터베이스의 ‘마스터키’와 같으니, 절대 잊어버리지
않도록 메모해두세요. 처음 접속 성공 후 “Connection Successful”이라는 메시지를 본다면, 이미 절반은 성공한 셈입니다.
Step 1 체크포인트 (이 단계에서 할 수 있어야 하는 것)
- Workbench(또는 DBeaver)에서 로컬 MySQL에 접속할 수 있다.
root비밀번호를 잊지 않게 관리할 수 있다(메모/비밀번호 관리 도구 등).- 샘플 DB(예: sakila/employees)를 준비하거나, 연습용 DB를 하나 만들 준비가 되어 있다.
Step 1 추천 실습 5개
- Workbench에서 새 연결(Localhost 127.0.0.1:3306)을 만들고 접속 성공하기
SELECT VERSION();실행해서 버전 확인하기- 연습용 DB 만들기:
CREATE DATABASE my_study; - DB 목록 보기:
SHOW DATABASES; - 연습용 DB 선택하기:
USE my_study;
Step 2: SQL 기본 문법 (CRUD) 익히기
SQL 입문 로드맵의 핵심인 문법 학습 단계입니다. SQL(Structured Query Language)은 데이터베이스라는 사서와 대화하는 언어입니다. 겁먹을 필요 없습니다. 영어 문장과 어순이 비슷하거든요.
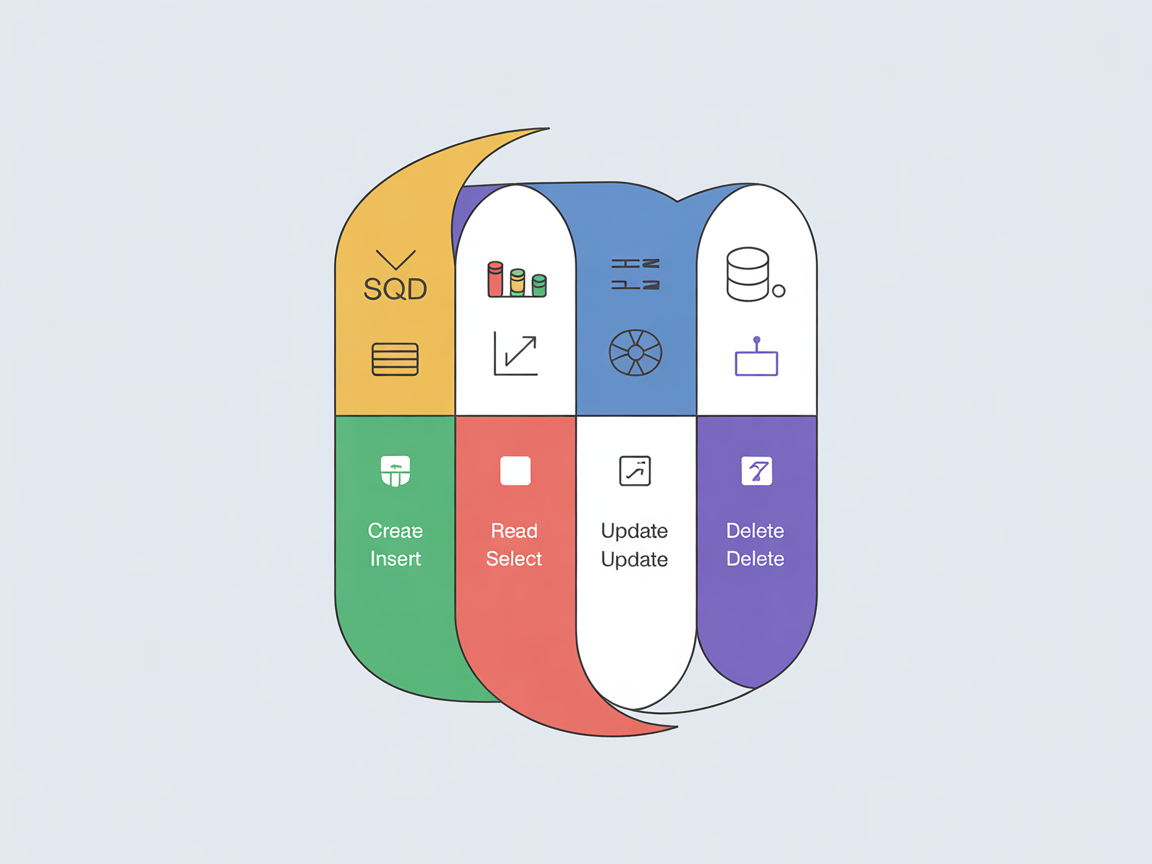
1. CRUD: 데이터의 탄생부터 죽음까지
모든 데이터 관리는 딱 4가지 동작으로 요약됩니다.
| 기능 | SQL 명령어 | 역할 | 비유 |
|---|---|---|---|
| Create | INSERT | 데이터 생성 | 새 회원이 가입함 |
| Read | SELECT | 데이터 조회 | 회원 명단을 확인함 |
| Update | UPDATE | 데이터 수정 | 회원 비밀번호를 변경함 |
| Delete | DELETE | 데이터 삭제 | 회원이 탈퇴함 |
2. 초보자는 SELECT에 먼저 집중하세요
실무(특히 운영 DB)에서는 무턱대고 데이터를 삭제(DELETE)하거나 구조를 변경(DDL)하는 행동이 매우 조심스럽습니다. 그래서 학습 초반에는 데이터를 안전하게
“조회”하는 SELECT에 먼저 집중하는 것이 좋습니다.
- SELECT & FROM: 무엇을(
SELECT), 어디서(FROM) 가져올지 정합니다.SELECT * FROM employees;(직원 테이블에서 모든 정보를 가져와라)
- WHERE (조건): 엑셀의 필터 기능과 같습니다.
WHERE salary >= 50000(연봉이 5만 불 이상인 사람만)
- ORDER BY (정렬) & LIMIT (제한): 데이터를 보기 좋게 다듬습니다.
ORDER BY hire_date DESC LIMIT 5;(입사일 기준 최신순으로 정렬해서 상위 5명만 보여줘)
[실전 예제 코드] “연봉이 50,000 이상인 직원의 이름과 연봉을 연봉 높은 순서대로 조회하고 싶다”면 이렇게 작성합니다.
SELECT first_name, last_name, salary
FROM employees
WHERE salary >= 50000
ORDER BY salary DESC;[부가 설명] SELECT *은 모든 컬럼을 다 가져오라는 뜻인데, 데이터가 수백만 건일 때는 도구가 느려지거나 화면이 멈춘 것처럼 느껴질 수 있습니다.
실무에서는 필요한 컬럼만 콕 집어서(SELECT name, email) 조회하는 습관을 들이는 것이 좋습니다. 또한 WHERE 절에는
LIKE 같은 유용한 연산자도 많으니 천천히 익혀보세요.
Step 2 체크포인트
SELECT / FROM / WHERE / ORDER BY / LIMIT조합으로 원하는 데이터를 뽑을 수 있다.AND / OR, 비교 연산(=,>,<)을 쓸 수 있다.LIKE로 간단한 문자열 검색을 할 수 있다.
Step 2 추천 실습 5개
- 급여가 특정 값 이상인 데이터만 조회하기 (WHERE)
- 최신 데이터 10개만 보기 (ORDER BY + LIMIT)
- 이름에 특정 글자가 포함된 사람 찾기 (LIKE)
- 조건 2개 이상 조합하기 (AND/OR)
- 필요한 컬럼만 선택해서 조회하기 (SELECT 컬럼 나열)
Step 2.5: 테이블 설계·데이터 타입·제약조건 (진짜 기초 체력)
많은 초보자가 SELECT는 어느 정도 되는데, 막상 “내 프로젝트 DB를 만들려고 하면” 멈춥니다. 이유는 간단합니다. 테이블을 ‘어떻게 설계하고 만들지(DDL)’를 제대로 안 배웠기 때문입니다.
1. 데이터 타입: “칸에 어떤 값이 들어가나?”
- 숫자:
INT,BIGINT(ID나 카운트 등에 자주 사용) - 문자:
VARCHAR(길이),TEXT(이름/이메일/설명 등) - 날짜/시간:
DATE,DATETIME,TIMESTAMP
2. 제약조건: “규칙을 DB가 대신 지켜준다”
- PRIMARY KEY: 각 행(row)을 구분하는 유일한 값(중복 불가)
- NOT NULL: 비어 있으면 안 되는 칸
- UNIQUE: 중복되면 안 되는 값(예: 이메일)
- FOREIGN KEY: 다른 테이블과 연결(관계의 핵심)
3. 최소 예제로 한 번에 감 잡기
“회원(users) + 주문(orders)” 관계는 가장 대표적인 연습입니다.
CREATE TABLE users (
user_id BIGINT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL,
created_at DATETIME NOT NULL
);
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id BIGINT NOT NULL,
total_amount INT NOT NULL,
created_at DATETIME NOT NULL,
CONSTRAINT fk_orders_users
FOREIGN KEY (user_id) REFERENCES users(user_id)
);[부가 설명] 이 Step 2.5를 이해하면 Step 3(JOIN/정규화)에서 “왜 테이블이 나뉘는지”가 훨씬 자연스럽게 연결됩니다.
Step 2.5 체크포인트
CREATE TABLE로 테이블을 만들 수 있다.- 대표 데이터 타입(
INT/VARCHAR/DATETIME)을 목적에 맞게 고를 수 있다. PRIMARY KEY,NOT NULL,UNIQUE개념을 설명할 수 있다.FOREIGN KEY가 “관계”를 만든다는 것을 이해한다.
Step 2.5 추천 실습 5개
- users 테이블을 만들고, 이메일 UNIQUE가 동작하는지 확인하기
- orders 테이블을 만들고, 존재하지 않는 user_id로 INSERT 시도해보기(FK 확인)
- 컬럼을 하나 추가해보기:
ALTER TABLE users ADD COLUMN phone VARCHAR(30); - 테이블 구조 보기:
DESC users;,SHOW CREATE TABLE users; - 간단한 데이터 5건 넣고(INSERT) Step 3에서 JOIN으로 묶어보기
Step 3: 데이터 연결과 구조의 이해 (관계형 DB의 꽃)
데이터가 하나의 엑셀 시트에 다 들어있다면 편하겠지만, 실제로는 수십 개의 테이블로 쪼개져 있습니다. 이 흩어진 조각들을 하나로 합치는 기술이 바로 JOIN입니다.
1. 왜 데이터를 쪼개나요? (정규화)
한 테이블에 직원 정보, 부서 정보, 월급 내역을 몽땅 넣으면 데이터가 중복되고 관리가 힘들어집니다. (예: 부서 이름이 바뀌면 수만 명의 데이터를 다 수정해야 함). 그래서 ‘직원 테이블’, ‘부서 테이블’로 나누어 관리하는데, 이를 정규화(Normalization)라고 합니다.
2. JOIN: 흩어진 데이터를 본드로 붙이기
나눠진 테이블을 필요할 때만 연결해서 보는 기술입니다.
- INNER JOIN (교집합): 두 테이블 모두에 정보가 있는 경우만 가져옵니다. (부서가 배정된 직원만 조회)
- LEFT JOIN (부분 집합): 왼쪽 테이블(기준)은 다 보여주고, 오른쪽 정보는 있으면 붙이고 없으면 비워둡니다. (부서가 없는 신입 사원도 모두 조회)
3. 연결 고리: Primary Key와 Foreign Key
테이블끼리 연결하려면 ‘고리’가 필요합니다.
- Primary Key (기본키): 주민등록번호처럼 나를 식별하는 고유한 번호 (중복 불가).
- Foreign Key (외래키): 다른 테이블의 기본키를 가리키는 값. 연결의 다리 역할을 합니다.
[부가 설명] JOIN을 처음 접하면 벤 다이어그램(집합 그림)을 떠올리는 것이 가장 이해가 빠릅니다. 실무에서는 3~4개 이상의 테이블을 한 번에 JOIN 하는 경우도
흔하므로, ON 뒤에 어떤 컬럼끼리 연결되는지(예: employees.dept_no = departments.dept_no) 명확히 파악하는 연습이 필요합니다.
Step 3 체크포인트
- INNER JOIN과 LEFT JOIN의 차이를 설명할 수 있다.
- JOIN 조건(
ON)이 “어떤 키끼리 연결하는지” 파악할 수 있다. - 정규화가 “중복을 줄이고 수정 비용을 낮추는 것”임을 이해한다.
Step 3 추천 실습 5개
- users와 orders를 INNER JOIN으로 합쳐 주문 목록을 출력하기
- LEFT JOIN으로 “주문 없는 사용자”도 함께 조회하기
- JOIN을 2번 이상 사용해 3개 테이블을 연결해보기(샘플 DB 활용)
- JOIN 없이 한 테이블에 모두 넣었을 때 중복이 생기는 예를 직접 만들어보기
- FK가 있을 때/없을 때 데이터 품질이 어떻게 달라지는지 비교해보기
Step 4: 중급 도약 – 함수와 서브쿼리
단순히 있는 데이터를 가져오는 것을 넘어, 데이터를 가공하고 요약하여 ‘정보’로 만드는 단계입니다.
1. 데이터 요약 (집계 함수 & GROUP BY)
상사에게 “전체 엑셀 파일 줘”라고 보고하는 사람은 없습니다. “부서별 평균 연봉이 얼마입니까?” 같은 질문에 답해야 하죠.
- 집계 함수:
COUNT(개수),SUM(합계),AVG(평균),MAX(최대값),MIN(최소값) - GROUP BY: 데이터를 특정 기준(부서별, 성별 등)으로 묶어줍니다.
2. 서브쿼리 (Subquery): 질문 속의 질문
“제일 돈을 많이 버는 직원의 이름을 알려줘”라는 질문을 해결하려면?
- 먼저 제일 많은 연봉 액수를 구한다.
- 그 연봉을 받는 사람을 찾는다.
이 과정을 한 문장으로 쓰려면 쿼리 안에 또 다른 쿼리(서브쿼리)를 넣어야 합니다.
3. 윈도우 함수 (Window Functions)
과거에는 복잡한 서브쿼리로 구하던 순위나 누적 합계를 이제는 ROW_NUMBER(), RANK() 같은 윈도우 함수로 쉽게 구할 수 있습니다. 중급으로 올라가는
강력한 무기입니다.
[부가 설명]
- WHERE vs HAVING 핵심:
WHERE는 “묶기 전(행 단위)” 필터,HAVING은 “묶은 후(집계 결과)” 필터입니다. - 중요:
GROUP BY가 있어도 일반 조건(행 조건)은WHERE에 쓰는 것이 보통 더 자연스럽습니다. 집계값(예: 평균 연봉)이 조건이면HAVING을 씁니다.
Step 4 체크포인트
COUNT/SUM/AVG로 요약 통계를 낼 수 있다.GROUP BY로 “기준별 집계”를 만들 수 있다.WHERE와HAVING의 차이를 정확히 설명할 수 있다.- 서브쿼리를 “질문 속 질문”으로 이해하고 쓸 수 있다.
- 윈도우 함수로 간단한 랭킹/순번을 만들 수 있다.
Step 4 추천 실습 5개
- 부서별 평균 급여를 계산하고, 평균이 특정 값 이상인 부서만 출력하기(HAVING)
- 가장 비싼 주문/가장 높은 급여 등 “최대값 대상 찾기”를 서브쿼리로 풀어보기
- 같은 문제를 윈도우 함수로도 풀어보기(ROW_NUMBER / RANK)
- 날짜별(월별) 주문 합계를 GROUP BY로 만들기
- 집계 결과를 정렬하고 상위 N개만 뽑기(ORDER BY + LIMIT)
Step 5: 성능 최적화와 고급 기능 (Advanced)
쿼리 결과가 1초 만에 나오느냐, 10분 뒤에 나오느냐는 천지 차이입니다. 대용량 데이터를 다룰 때 꼭 필요한 쿼리 최적화의 기초입니다.
1. 인덱스(Index): 책의 목차 만들기
두꺼운 전공 서적에서 특정 단어를 찾을 때, 처음부터 끝까지 훑는 것(Full Scan)보다 뒤편의 ‘색인(Index)’을 보는 게 훨씬 빠르죠? DB에도 자주 찾는 컬럼에 인덱스를 걸어두면 검색 속도가
비약적으로 빨라집니다. 단, 인덱스가 너무 많으면 데이터를 저장(INSERT)하거나 수정(UPDATE)할 때 느려질 수 있으니 주의해야 합니다.
2. 트랜잭션(Transaction): 완벽하지 않으면 취소해
계좌 이체를 생각해보세요. 내 돈은 빠져나갔는데 상대방에게 입금이 안 되면 큰일이죠? 트랜잭션은 ‘모두 성공(COMMIT)’하거나, 하나라도 실패하면 ‘처음으로 되돌리기(ROLLBACK)’하는 안전장치입니다.
[중요] MySQL은 보통 InnoDB 엔진을 사용하며(InnoDB가 기본인 환경이 많음), 이때 트랜잭션이 제대로 동작합니다. 학습 단계에서는 “내 테이블이 InnoDB인지”를 확인해보는 습관이 좋습니다.
3. 실행 계획 확인 (EXPLAIN)
내가 짠 쿼리가 느리다면? 쿼리 앞에 EXPLAIN을 붙여 실행해보세요. DB가 데이터를 어떻게 찾고 있는지(인덱스를 탔는지, 전체를 훑는지) 힌트를 보여줍니다.
[부가 설명] 초보자 단계에서 인덱스를 직접 설계할 일은 드물지만, “왜 내 쿼리가 느리지?”라는 의문이 들 때 인덱스의 유무를 의심해볼 수 있어야 합니다. 또한 트랜잭션의 ACID(원자성, 일관성, 고립성, 지속성) 성질은 면접 단골 질문이기도 하니 개념 정도는 숙지해두시는 것이 좋습니다.
Step 5 체크포인트
- 인덱스가 “조회는 빠르게, 쓰기는 느리게” 만들 수 있음을 이해한다.
EXPLAIN으로 “인덱스를 쓰는지/풀스캔인지” 확인하는 습관이 있다.- 트랜잭션이 왜 필요한지(중간 실패 시 롤백) 설명할 수 있다.
Step 5 추천 실습 5개
- 느린 SELECT를 하나 만든 다음
EXPLAIN으로 확인해보기 - WHERE에 자주 쓰는 컬럼에 인덱스를 추가한 뒤 EXPLAIN 결과가 어떻게 바뀌는지 보기
- 트랜잭션 실습:
START TRANSACTION→ INSERT 2개 → ROLLBACK/COMMIT 해보기 - 같은 조건이라도
SELECT *vs 필요한 컬럼만 조회했을 때 체감 비교하기 - JOIN이 많아질수록 느려지는 이유를 EXPLAIN으로 관찰해보기
효율적인 학습 방법론 (How to Study)
이론만 파서는 절대 실력이 늘지 않습니다. 수영을 책으로 배울 수 없듯이, SQL도 직접 키보드를 두드려야 합니다.
- 프로젝트 기반 학습 (PBL): 거창할 필요 없습니다. ‘나만의 가계부’, ‘우리 집 도서 대출 시스템’ 등을 기획하고 테이블을 직접
설계(
CREATE)해보세요. 내 통장 내역을 넣고SUM으로 지출 합계를 구해볼 때 진짜 실력이 듭니다. - AI 코딩 튜터 활용: 쿼리를 짜달라고만 하지 말고, “이 쿼리에서 왜 에러가 났어?”, “이걸 더 빠르게(최적화) 고쳐줘”처럼 “이유”를 묻는 방식으로 활용해보세요.
- 꾸준한 문제 풀이: 프로그래머스, HackerRank 같은 사이트의 SQL 문제를 하루에 한 문제씩 풀어보세요. 문법을 조합하는 응용력이 크게 성장합니다.
공부 루틴 추천 (초보자용)
- 하루 30~60분: SELECT 문제 1개 + 해설 정리
- 주 2회: JOIN 문제 1개 이상
- 주 1회: “테이블 설계(DDL)” 작은 연습(새 테이블 1개 만들기)
- 주 1회: GROUP BY/HAVING 통계 문제 1개
- 월 1회: 작은 프로젝트(가계부/도서대출/주문시스템 중 1개) 기능 1개씩 확장
결론
환경 설정부터 성능 최적화까지, MySQL 학습 순서 5단계를 살펴보았습니다. 요약하자면 다음과 같습니다.
- 두려움 없애기: GUI 툴로 쉽게 설치하고 샘플 데이터를 깐다.
- 기본기 다지기:
SELECT와WHERE로 원하는 데이터를 뽑아본다. - 진짜 기초 체력: 데이터 타입/제약조건으로 테이블을 직접 설계한다.
- 구조 이해하기:
JOIN으로 테이블을 연결해본다. - 정보 만들기: 함수와 서브쿼리, 윈도우 함수로 통계를 내본다.
- 전문가 되기: 인덱스와 트랜잭션, EXPLAIN으로 성능과 안정성을 챙긴다.
SQL은 개발자뿐만 아니라 마케터, 기획자, 데이터 분석가 모두에게 강력한 무기입니다. 오늘 바로 MySQL Workbench를 열고, 여러분의 첫 번째 SELECT 문을 실행해
보세요. 그 작은 엔터 한 번이 데이터 마스터로 가는 위대한 첫걸음이 될 것입니다.
참고 자료 및 링크
자주 묻는 질문 (FAQ)
Q: 데이터베이스(DB)를 처음 배우는데 꼭 명령어를 외워야 하나요?
A: 아니요, 처음부터 모든 명령어를 외울 필요는 없습니다. 다만 “자주 쓰는 패턴(SELECT/WHERE/ORDER BY/LIMIT)”은 반복하면서 자연스럽게 익는 것이 가장 좋습니다.
Q: WHERE 절과 HAVING 절의 차이점은 무엇인가요?
A: WHERE는 그룹화 전(행 단위) 필터, HAVING은 그룹화 후(집계 결과) 필터입니다.
평균/합계 같은 집계값 조건은 HAVING을 사용합니다.
Q: 쿼리 속도가 너무 느린데 어떻게 해야 하나요?
A: 가장 먼저 EXPLAIN으로 실행 계획을 확인해보세요. 그리고 WHERE/JOIN에 자주 쓰는 컬럼에 인덱스가 적절히 걸려 있는지 점검하는 것이 기본 출발점입니다.